Archive
Page Positional Gallows, Mk. II
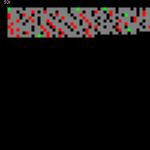
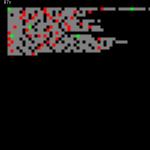
Here is a new set of images, for each of the folios in the VMs, that shows the positions of the various gallows glyphs.
To clarify – these “positions” are not the positions as seen on the image scans of the manuscript itself, they are the positions in terms of glyph position along each line.
The difference between these and the ones in the previous post is that these have Gallows “f” coloured blue, “g” coloured green, and the other gallows coloured red (as before).

































































































































































































































Frequency Distributions for Phonetic Codes
Knox took the time to plot the frequency distributions from this post, where I looked at the theory that the VMs words are phonetic codes. Here are his results:
Where not included in the title, comparisons are to the Herbal Sections. VMs is in blue-black.
Comparison of phonetic code frequencies between VMs sections and various known texts.
With only 40 words to translate, there cannot be a meaningful series but it would be interesting to see the actual words in position, anyway. If this only shows the power of Genetic Algorithms to match something regardless of significance, why does the old Latin Herbal make the best matches to the Herbal and Astrological sections?

f75r cures, pregnancy, life and death – Latin Plainchant
Here is a result obtained using a Genetic Algorithm to match the text on f75r to Latin. The training corpus I used was a large file of Latin plainchant (the idea being that repeated “words” in the VMs show similarities to chant).
First, here is the folio with the translated words overlain in red:

Folio f75r decrypted as Latin plainchant
The genetic algorithm searched for a set of glyphs that each matched to a pair of Latin letters.
Most of the decrypted words are valid Latin and match words in the plaintext I used to train the GA. Some are Latin but do not appear in the plaintext. The other, invalid, words could be caused by errors in the pair matching.
Or the whole thing could well be nonsense! This is likely – I asked Joel Stevens to translate some of the Latin, and here is what he said:
On first inspection, it seems to be random non-sense. For example:
recita lugete vena dans veta ia debent lustrata liteWould mean: Recite! Mourn! Blood-vessel giving. Forbid! Oh, they owe things that were purified by the lawsuit.
I’m not really sure how to make sense of it. I don’t see anything that stands out as an obvious sentence. Maybe some words are filler and need to be dropped… or maybe there is a hidden order that needs to be found (assuming these are the correct words).
Here is the Latin:
piraextita recita' lugete' idpirata lucrte vena' dans' veta' ia' debent' lustrata' vanagete vamirata lite' lugens' esnt levata' nuta' gens' veanta rochum' nogete le dato' uascie excita' curi gent na veta' le veta' luedicta veexti vata' arta' te' chum no' no' amicta' luedet luga' mori' edente' noga date' reri' lugens' feta' luedicta luga' morata' luaena uechum vana' lugete' ad' nt vana' luga' pate vata' lugertta audita' lugens' vita' curata' resona' lupina' feta' lumina' lugeum veon lugete' no' vana' lant aule lucrte ista' veta' lugens' vita' na ruri' mena' strata' luedicta lugens' nota' luedicta na lugent' reti' vena' date' vageas dedita' lugent' nota' veta' te' no' iret' veta' na no' vena' luga' morata' edicta' lumina' lumina' lumina' lumina' lugens' novena' lace' si' educta' lugens' na novena' lugens' vita' lugens' ruti' sita' lans' lugens' luuacinota lacium vana' pant' le vena' reista luga' aurata' lugete' verata nt ha' urgens' ad' revena lugens' vana' morati' vemota curatita dant' bunt' id' ncnt vena' lugeas pant' vesata lunt vena' lunt ruchum este' late' nota' luaerata lunt veta' luga' veta' ulta' lugens' ti iu' veta' lute vata' stri sschum veta' lumicium clrechum vata' poma' le sebete no' te' ut' sati' veta' lugens' vana' le acta' gete vana' tute' mori' aeri' luedet lugent' deri lunt vana' lugeas lugens' no' edet' luuatita lans' vato te' no' lans' orta' luedicta id' na luedicta strata' tuas' dans' no' veno dans' no' luia' date' muta' gnsiurte duno' luca' alti' vena' resina' date' ruti' rurata na sunt' errata' morata' luedet pant' no' dace' veto' lunt nt amicta' luedicta strata' dans' fisi' na uachns no' recina lunt dans' novata' luedicta vana' lucrum' lu' dans' irquta lumita lugens' vaga' lugent' dans' vana' resino vena' reti' nodo' aurata' lumita vita' lugete' vena' vata' lumini' lumina' dant' na locuta' dant' vena' lugens' date' pena' vena' lugete' vena' usta' luedet nt vena' lunt vana' lugens' ferata rorata' dalias pr' nomina' resi date' ruta reti' ruti' no' gens' nomina' lugens' ambita' lugens' date' date' vena' lugens' nona' pant' mirata luedicta luncta' reti' ruti' date' date' na lumina' na ambita' lumina' luedicta lumiista nt lumirata luedicta lumina' lumina' lumirata usta' serata' luedicta lumirata noedicta ruri' ncusta date' vena' lugens' vena' dant' edicta' te' vena' paedicta luedicta rucina luga' na edicta' ma aurata' lumina' luedicta luiget luigicta date' serata' vagete nona' lugens' fiti ruti' nona' sprata lans' rerata lumina' rurata renona ruti' ruut nochns ha' date' na derata orta' lumita rerata lalint ruta rurata lumena rurata rechns lumita lumina' veno lumina' dans' vena' eg plnt vana' noti'
Does the language of Dante fit the VMs?
Having spent many pleasurable hours checking various exotic cipher and code ideas, none of them remotely fits when using a GA, except one. My faith in the GA technique is that it very quickly gives an idea of how well a code/cipher theory fits the VMs text.
The one cipher idea and plaintext language that does notably better than all others is an nGram mapping with the language of Dante as the plaintext. This is a form of early Italian, and it produces results significantly better than all other languages tried with nGrams, including Latin, German, English, Spanish, Dutch, Chinese etc. .
I’ll post some results from this nGram/Dante GA later.
There is a significant obstacle with applying computational techniques to the VMs, and that is the machine transcriptions of the VMs text. Basically they differ substantially, to the extent that statistics obtained with, say, EVA do not match well with statistics obtained with, say, Voyn_101. A particular problem is glyph bloat … my opinion is that GC’s Voyn_101 transcription contains many more glyphs than the scribes were actually using. Little differences between the ways of writing “9″ for example, are classified as different glyphs. This plays havoc with statistical analysis. Thus I have a procedure that filters the Voyn_101 and remaps e.g. those multiple “9″ glyphs to the same glyph. This allows a smaller, more realistic, search space. But it still doesn’t address the question of what strokes make up a single glyph, which is often open to interpretation. Thus any nGram mapping procedure has to allow for at least 1-3 Grams in the Voynich to be reasonably sure of covering the glyph correspondences properly.
Here is an extract of the Dante Alighieri text that matches decently using nGrams to the VMs:
Cjant Prin
A metàt strada dal nustri lambicà
mi soj cjatàt ta un bosc cussì scur
chel troj just i no podevi pì cjatà.
A contàlu di nòuf a è propit dur:
stu post salvàdi al sgrifàva par dut
che al pensàighi al fa di nòuf timour!
Che colp amàr! Murì a lera puc pi brut!
Ma par tratà dal ben chiai cjatàt
i parlarài dal altri chiai jodùt.
I no saj propit coma chi soj entràt:
cun chel gran sùn che in chel moment i vèvi,
la strada justa i vèvi bandonàt.
Necuàrt che in riva in su i zèvi
propit la ca finiva la valàda
se tremaròla tal còu chi sintèvi
in alt jodùt iai la so spalàda
vistìda belzà dai rajs dal pianèta
cal mena i àltris dres pa la so strada.
(This is modified from a reply to Knox who commented on an earlier post.)
How about a “Verbose Homophonic cipher”?
I’ve had a bit of hiatus from the VMs, but it’s always popping up in my mind and niggling me, even when I haven’t got time to spend on it. The latest niggle was the idea that the VMs scribe used a set of simple tables that showed how to convert plaintext letters into codes. So, in an example table, letter “A” is written “4oh”, letter “B” is written “8am” and so on. Also, spaces in the plaintext have their own code. Veteran VMs researcher Philip Neal informed me that this is called a “verbose homophonic cipher”.
Elaborating on the idea: the scribe uses one of the set of tables for each folio s/he is writing. To encipher the plaintext onto the folio, it’s simply a matter of writing down the VMs “word” for each letter in the plaintext word. If there is more space on the line for the next plaintext word, the scribe writes down the code for space, and then the codes for the letters in the next word. Long spaces are written by writing the code for space more than once … The next line is used for the next word, and so on.
On the next folio, a different table may be used.
It’s hard to imagine the justification for such a scheme, but it does appear (at least initially) to fit some of the features of the VMs script (especially the repeating VMs words often seen).
I made a quick test that looks at VMs word frequencies on a single folio (in the Recipes section, which has the densest text). These showed a word frequency distribution that looks similar to the letter frequency distribution in Latin, apart from the most frequently occurring word (which is much more frequent) and which it is suggested would code for a space in the cipher.
However, on a typical folio, there are usually many more VMs words than there are plaintext letters. So the scheme has to be extended to allow the scribe a choice between several different VMs words to encode a single letter. Each table must have a set of words appearing in each plaintext letter column. Something like this:
| Plaintext | (space) | a | b | … |
| VMs words | 8am ay okoe | 4ohoe 2ay 1coe | faiis 4ay oka | … |
If this is indeed the scheme, one would expect to see patterns in the VMs word sequences that match patterns seen in the letter sequences of e.g. Latin words. Also, as Philip Neal pointed out, patterns like “word1 word2 word2 word1” would indicate a plaintext letter sequence of either “vowel consonant consonant vowel” or vice versa.
Looking through the whole of the VMs for sequence patterns (on the same line of text), I found the following:
- There are no 4 word sequences that repeat at all
- There are only four 3 word sequences that repeat, and each only twice
- There are no sequences at all of the form “xyyx”
(all of which I find rather surprising, and thought provoking).
So it looks like this hypothesis is dead in the water, and can be ticked off that long list of “things it might have been but in fact don’t fit”!
(It turns out that Elmar Vogt has been working on a related, but more sophisticated, idea which he describes on his blog and is called a “Stroke Theory”.)
T/O Maps, the Moon and Carthage
Consider the three T/O maps (thanks to Rich Santa Coloma for this suggestion), depicting the Earth (or World) in the VMs (on f67v2, the Rosettes, and f68v3). Looking at f67v2 there is a channel between the moon and one of the T/O map quadrants, labeled “ohay aeck oehaN”. The same quadrant is labelled “ohay” on the Rosettes. It makes sense that the Earth is shown like this on both folios – away and to the side – as these folios are dedicated to illustrations of the sun, moon etc. and (perhaps) paradise or the garden of earthly delights, respectively. Let’s come back to this later – specifically the significance of the label “ohay” with the Moon. 

The T/O map on f68v3 can be compared with a map from 1472 , and it’s tempting to match “oko8oe” to “Africa” or “Cham”.


However, the Asia part of the map on f68v3 is labeled with a set of words, rather than a single word that might be “Asia” or “Sem”. So perhaps this is a list of prominent place names in Asia. Perhaps the labels on the Europa and Africa quadrants are also prominent place names? Here’s a contemporary map that shows Africa, Europa and Asia (from 1483):

In Africa, we see the city of Cartha (Carthage). Carthage is even more prominent in this map dating from 1110:

So, the conjecture for this T/O map on f68v3 is that it is showing prominent (or significant) place names in each continent, and that “oko8oe” = “cartago”. This fits nicely (of course) with the “ok-” = “ca-” prefix theory.
Gallows
The significance of the Gallows characters
There are 19 gallows characters in Glen Caston’s Voyn_101 transcription:
 Unlike the majority of standard VMs characters/glyphs, these are unusual in appearance and some appear to be composites of other gallows with the “c” and/or “cc” characters. My opinion is that the 2nd and 4th in the above set are the same, as are the 1st and 8th. This reduces the count to 17. An attractive proposition is that these are simply the capital letters in an alphabet of 17 letters. Indeed, the gallows characters often appear initially in the first word on a page. However, they also appear within VMs words, which is odd – unless a) the VMs words are not words at all, orb) they have been assembled unusually (e.g by anagramming).
Unlike the majority of standard VMs characters/glyphs, these are unusual in appearance and some appear to be composites of other gallows with the “c” and/or “cc” characters. My opinion is that the 2nd and 4th in the above set are the same, as are the 1st and 8th. This reduces the count to 17. An attractive proposition is that these are simply the capital letters in an alphabet of 17 letters. Indeed, the gallows characters often appear initially in the first word on a page. However, they also appear within VMs words, which is odd – unless a) the VMs words are not words at all, orb) they have been assembled unusually (e.g by anagramming).
Landini’s Challenge
An excerpt from Landini’s challenge text (text he generated using an undisclosed method, supposed to replicate the features of the VMs text):
qopchdy chckhy daiin ¬ ½shxam chor otechar okcharain ryly sheodykeyl
sheodykeyl daiin shd okaiin qokain qokal yteoldy otedy qokydy opchedy
otal oldar chor lkeedol eer ol dair chedy daiin ockhdar cpheol chedy
xar qokaiin y chedy kshdy ololdy aiin char y okeey oldar qokaiin lsho
daiin olsheam qoeey chedy dchos pshedaiin shedy d qol key sheol or
cpheeedol qokedy qokaiin daiin cthosy chedy ar aiir chedy teeol aiin
cheey y cheam oky qokaiin daldaiin loiii¯ ar shtchy chedy aldaiin
ydchedy daiin shd okaiin qokain daiin qotcho chedy daiin lchy olorol
otedy qockhor shol daiin paichy chedy ar shdair chedal chedy kchdaldy
chckhy otakar qokedy s qooko chor daiin otcholchy chedy daiin koroiin
qokain qokedy kosholdy ol kchedy kshdy qokaiin ar shaikhy olaldy seees
ar oteodar chedy oteeol shedy daiin key dain daiin keeokechy chedy
lchey ail lchedy sches ol dsheeo otol odaiin qokain daiin sheeod chshy
chedy qoekedy tair sain qocheey aiin cheey chaiin ols shedy sheolol
daiin lcheol chedy daiin pchoraiin oshaiin chedy lchey lor sal aiin
cheey y dsheom shedy todydy cheor saiin shdaldy daiin ofchtar daiin
Here are some thought-provoking results from analysing the text, as suggested by Knox, the VM text, and comparisons with English, Latin, German, French and Spanish. These use a new form of the Genetic Algorithm, described below.
Summary
It looks to me like that Landini either generated his text from a transcription of the VM itself, or his algorithm for generating that text is a good emulation of the encoding process used in the VM. In other words the Landini “language” is a good candidate as a plaintext language for the VM, as opposed to the European languages tested.
Results
Here is a table which shows the GA’s efficiency at converting/translating between Voynich, Landini, and the other languages.

(In the table, the best possible score is 1.0 – see below for an explanation)
Asking the GA to translate English to English, or Latin to Latin, etc. results in a high efficiency score, as expected. Note that the Landini to Landini efficiency is 0.97 – almost perfect.
The GA performs moderately at converting between the languages and the Landini text. But what is most striking (to me) is the good efficiency for converting Voynich to Landini (0.74) and Landini to Voynich (0.89)
Some Notes on the table
To look at this I revised my GA code so that it was more flexible, and I jettisoned the use of separate dictionaries. Here is how the GA now functions. It can convert/translate between any language text samples.
1) Two text files are read in: the “source” text, and the “target” text. This could be, for example, a source file containing Landini’s text, and a target file containing Spanish text, if we want to convert from Landini to Spanish.
2) The text in each file is processed separately, producing two word lists, and two sets of n-Gram frequency tables.
3) The chromosomes are generated with random mappings between the source n-Grams and the target n-Grams
4) The GA evolves the chromosomes by trying to maximise their cost. The difference now is that when a target word is generated from the source text using the mappings, it is looked up in the target word list created in 2) above, rather than in a separate dictionary.
5) After training, the best chromosome can have a maximum cost value of 1.0, which would correspond to a perfect conversion between the source text and the target text (i.e. every word produced from the source text is found in the target text dictionary)
6) So we can feed the GA with two identical texts, and after training the score of the best chromosome should be 1.0, and indeed it approaches that (it doesn’t quite get there because only the top 100 n-Grams are translated, and so some characters in the source text cannot be translated).
7) The word and n-Gram frequency lists are made from the entirety of each text, but (for this exploratory study) the training takes place on only the first 50 “words” in the source text, and uses only the first 100 n-Grams for mapping. Thus if the 50 words of Voynich chosen contain several rare characters, then for those the mapping will fail because those rare characters do not appear in the n-Gram list, and this will result in a lower score.
8) In all cases the “X->X” score in the table (i.e. the diagonal) represents the best score possible for that language, and is a normalisation for the other numbers in the table. I should really revise the table and divide out the off-diagonal scores by the diagonal normalisations.
9) An improvement would be to configure the n-Gram list to be, say, 200 long, and use more source (Voynich) words for the training. The downside of this is mainly execution speed.
10) These runs were with n-Grams up to 3: it would be better to go to 4 at least.
11) I think Landini gets good scores because the character set he uses is very small. Knox comments ” A factor must be that the Landini Challenge has built-in frequency matches to any transcription of the VMs. Also, there is no meaningful correspondence in the letter sequence of one word to another in Landini. The difficulty fits what I said the VMs may be.”
Voynich Herbs
Edith Sherwood has a web site where she details compelling possible identifications for the plants depicted in the “herbal” pages of the VM.
Dana Scott’s page also has plausible identifications for the plants.
As has often been pointed out, if we look at the first Voynich “word” that appears on each page of the herbal part of the VM, we find that those words are unique, or appear elsewhere very rarely. It thus seems reasonable that the words may be the names of the plants depicted.
The GA was set up to find a set of n-Gram mappings that would convert a list of 111 Voynich first herbal words into Latin/English or Spanish. For this, dictionaries of Latin, English and Spanish herb/plant names were used.
The GA sought a mapping that would convert all the Voynich words for herbs/plants into as many valid plaintext (Spanish, English, Latin) words as possible. The best result was for a mixed English/Latin dictionary (see table): 31 of the 111 Voynich words were converted, about 30% success rate.
(One should never expect 100% success, due to missing names in the dictionary, transcription errors, missing n-Grams, incomplete n-Grams etc..)
The results are shown below in tabular form, together with Dana Scott’s and Edith Sherwood’s identification. The first column shows the folio in the VM, the second shows the first Voynich word on that folio. For the GA identification columns (3 and 4) the Voynich mapped word is shown, in quotation marks if not found in the associated dictionary, and in bold if found in the dictionary.
Note that, probably unsurprisingly, nowhere do the IDs from the GA in Spanish, English/Latin and Scott/Sherwood, agree! NOT YET, anyway 🙂
(What amuses me about about this mapping technique is that it tends to produce words that sound plausible in the target language. E.g. for f4r the Latin/English word “paptise” sounds like a valid word.)

{kind=link}