Archive
Fun with Grove Words and Cipher Wheels
What is a Grove word? The answer is a little fuzzy, but simplistically a Grove word is a VMS word that begins with one of the gallows glyphs. These words are often page or paragraph initial. Emma May Smith has a good explanation in her recent blog entry.
Mr. Grove observed the peculiar feature that some words beginning with a gallows glyph are also valid words if you remove the gallows glyph. For example, the word EVA kodaiin starts with gallows k, and odaiin is also a valid word.
It turns out that if you look at all words in the VMS, 46% of them have this property: remove the first glyph and you are left with a valid VMS word. Compare this with English, where only around 8% of words produce valid words if you remove the first letter. Making up the 46% we have 38% from non-Grove words (i.e. non-gallows initial), and 8% from Grove words.
To round out the statistics, about 13% of all VMS words have an initial gallows glyph.

Consider the nine wheels above, where one of the wheels contains gallows glyphs, and the other wheels contain other glyphs. These wheels can be selected in 29 -1 i.e. 511 different ways, to make words of length between 1 and 9.
The probability of selecting wheel 3 as the first wheel for the word is about 12.5%. In other words, with these 9 wheels, 12.5% of the time we’d create a gallows-initial “Grove” word – very close to what we observe in the VMS (13%). In fact, this figure of 12.5% is independent of the number of cipher wheels: as long as there are at least three wheels and they are used left to right, and the gallows glyphs fully occupy the third wheel, then 12.5% of the generated words will be Grove types.
As a corollary, it’s clear that for Grove types generated with the wheels, removing the first glyph will produce a valid word, as it is equivalent to generating a word starting at wheel 4 or later.
So what of the 54% of VMS words that are non-Grove, i.e. removing the initial glyph does not produce a valid VMS word? This can be explained if the number of different words used and written in the VMS is simply less than the total number of possible words that the author’s wheels can produce. What is the expected vocabulary size if we know there are 7,552 words written in the VMS (Takeshi), and we are missing 54% of them? It is simply 1.54 x 7,552 = 11,630 words, or thereabouts.
(Aside: the wheels above could just as easily be represented and used as a table with nine columns.)
In summary, “Grove” words (gallows initial) are ~13% of all words in the Voynich manuscript, and this fraction is what you’d expect if the text was produced using cipher wheels.
Word Length Distributions
In the previous blog post, we looked at the distribution of word lengths in the EVA transcription, and compared it with the binomial distribution for 9, as per the work of Stolfi. They matched well enough, as I had denoted EVA ch, sh, ain, aiin and qo as single glyphs, in a similar fashion as Stolfi:
For this page, we will define symbol as Currier did; i.e. EVA ch ans sh will be counted as single symbols, and so are EVA cth, ckh, etc..
https://www.ic.unicamp.br/~stolfi/voynich/00-12-21-word-length-distr/
i.e. he reduced some of the EVA glyph sequences to single symbols.
Without making these reductions, so leaving the EVA transcription unchanged, the distributions of course tend to higher values. As a check of my sanity, Marco Ponzi was kind enough to send me a list of VMS words he’d extracted from the ZL transcription, so that I could compare it with the words I extracted from the Takaheshi EVA. In the following plot I show the three word length distributions: EVA, ZL and the reduced EVA with ch, sh, ain, aiin and qo as single glyphs.
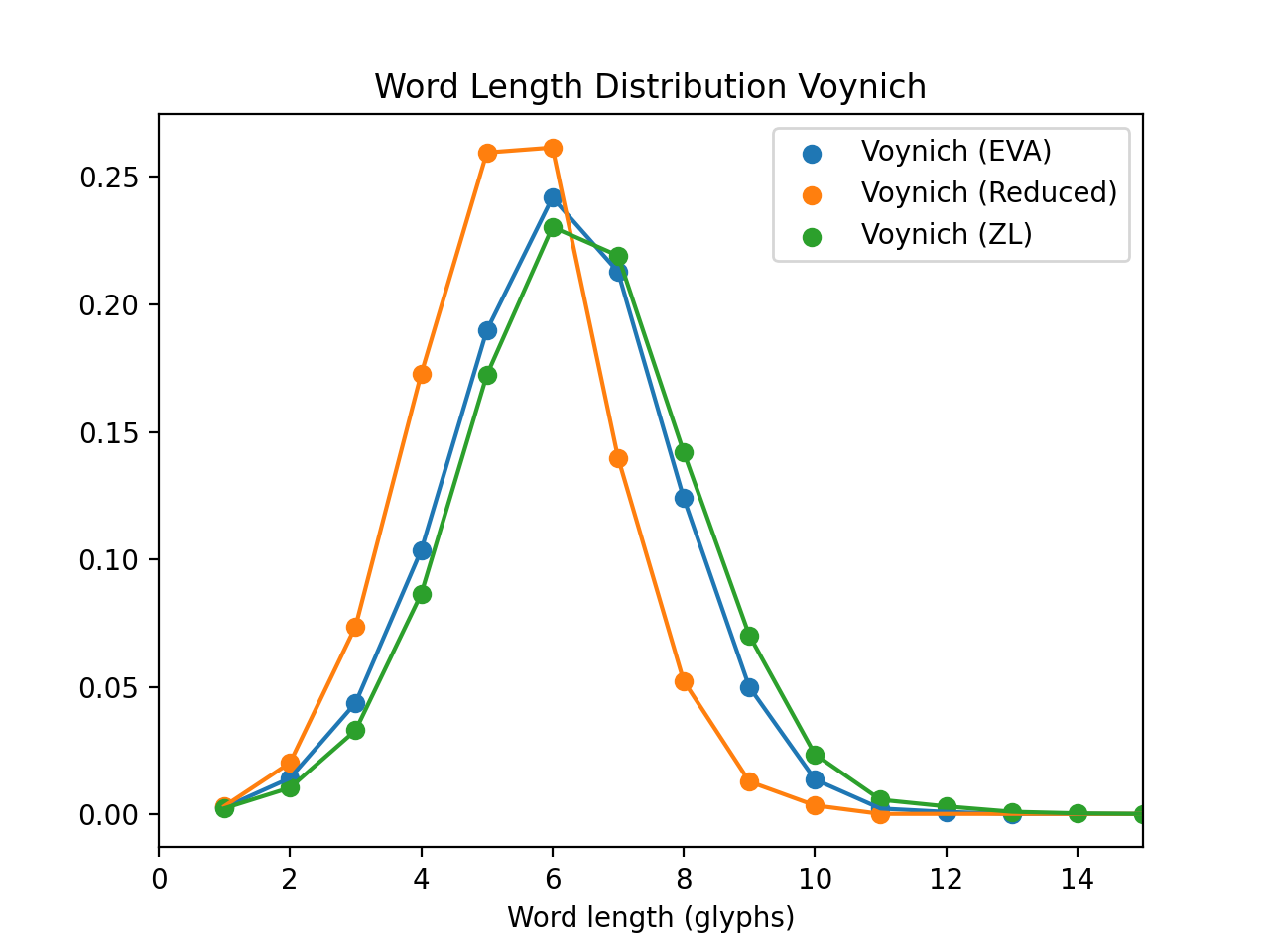
Reassuringly, the EVA and ZL (green and blue curves) match quite well, as they should, and the Reduced matches Stolfi’s result. (Curiously, the ZL transcription has a total of 8078 different words, compared with 7552 for Takaheshi EVA – which warrants further investigation.)
The EVA distribution now matches a binomial of (n=12,p=0.5), i.e. using 12 cipher wheels with a probability of 50% for a glyph being used from each wheel.

Nine Cipher Wheels
UPDATE (12 Aug 2021): the plots and results discussed in this post used a version of EVA that replaces some common glyph sequences by a single glyph, namely ch, sh, ain, aiin, and qo. Clearly, this tends to reduce the average word length. A later post will discuss the distributions obtained with words without this simplification.
The lengths of VMS words follow the binomial distribution for 9, as observed by Stolfi, and as discussed in Rene’s recent paper. This binomial distribution can be obtained from a set of 9 cipher wheels, where each wheel has a 50% chance of contributing one of its glyphs to the word being assembled, and the lengths of the resulting words plotted:

In the above plot, the orange line shows the distribution of word lengths from EVA, and the blue line shows the distribution of word lengths obtained by using the following set of 9 cipher wheels to generate a large number of random words:

With the cipher wheels shown, about 50% of the generated words will contain a gallows glyph, and this is, perhaps not coincidentally, the case in the VMS text, too.
Using the same technique as applied in my earlier blog post, where I looked at the counts between gallows glyphs in the VMS text, we can look at the same distributions for words generated with the above wheels, assembled into lines of text, and ignoring spaces between words. The results are very similar, and shown below.
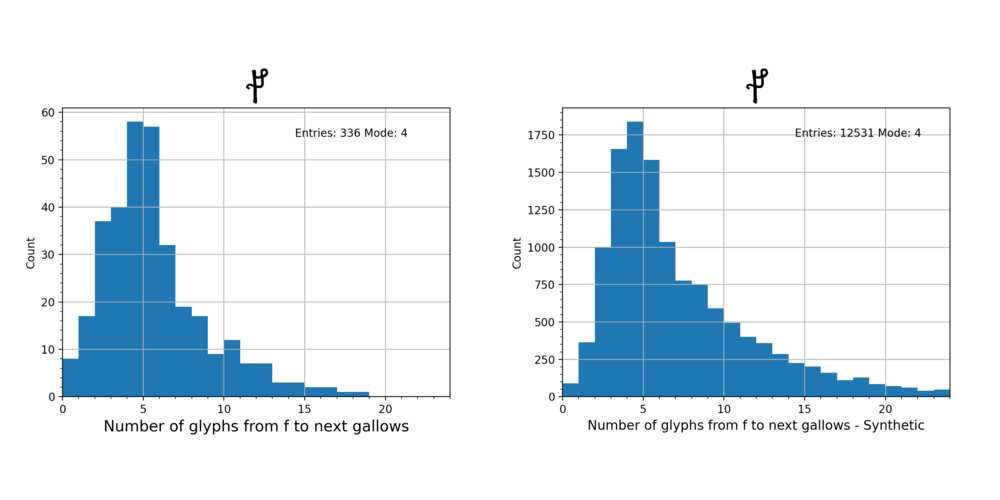
Here are the others:



Does the language of Dante fit the VMs?
Having spent many pleasurable hours checking various exotic cipher and code ideas, none of them remotely fits when using a GA, except one. My faith in the GA technique is that it very quickly gives an idea of how well a code/cipher theory fits the VMs text.
The one cipher idea and plaintext language that does notably better than all others is an nGram mapping with the language of Dante as the plaintext. This is a form of early Italian, and it produces results significantly better than all other languages tried with nGrams, including Latin, German, English, Spanish, Dutch, Chinese etc. .
I’ll post some results from this nGram/Dante GA later.
There is a significant obstacle with applying computational techniques to the VMs, and that is the machine transcriptions of the VMs text. Basically they differ substantially, to the extent that statistics obtained with, say, EVA do not match well with statistics obtained with, say, Voyn_101. A particular problem is glyph bloat … my opinion is that GC’s Voyn_101 transcription contains many more glyphs than the scribes were actually using. Little differences between the ways of writing “9″ for example, are classified as different glyphs. This plays havoc with statistical analysis. Thus I have a procedure that filters the Voyn_101 and remaps e.g. those multiple “9″ glyphs to the same glyph. This allows a smaller, more realistic, search space. But it still doesn’t address the question of what strokes make up a single glyph, which is often open to interpretation. Thus any nGram mapping procedure has to allow for at least 1-3 Grams in the Voynich to be reasonably sure of covering the glyph correspondences properly.
Here is an extract of the Dante Alighieri text that matches decently using nGrams to the VMs:
Cjant Prin
A metàt strada dal nustri lambicà
mi soj cjatàt ta un bosc cussì scur
chel troj just i no podevi pì cjatà.
A contàlu di nòuf a è propit dur:
stu post salvàdi al sgrifàva par dut
che al pensàighi al fa di nòuf timour!
Che colp amàr! Murì a lera puc pi brut!
Ma par tratà dal ben chiai cjatàt
i parlarài dal altri chiai jodùt.
I no saj propit coma chi soj entràt:
cun chel gran sùn che in chel moment i vèvi,
la strada justa i vèvi bandonàt.
Necuàrt che in riva in su i zèvi
propit la ca finiva la valàda
se tremaròla tal còu chi sintèvi
in alt jodùt iai la so spalàda
vistìda belzà dai rajs dal pianèta
cal mena i àltris dres pa la so strada.
(This is modified from a reply to Knox who commented on an earlier post.)
How about a “Verbose Homophonic cipher”?
I’ve had a bit of hiatus from the VMs, but it’s always popping up in my mind and niggling me, even when I haven’t got time to spend on it. The latest niggle was the idea that the VMs scribe used a set of simple tables that showed how to convert plaintext letters into codes. So, in an example table, letter “A” is written “4oh”, letter “B” is written “8am” and so on. Also, spaces in the plaintext have their own code. Veteran VMs researcher Philip Neal informed me that this is called a “verbose homophonic cipher”.
Elaborating on the idea: the scribe uses one of the set of tables for each folio s/he is writing. To encipher the plaintext onto the folio, it’s simply a matter of writing down the VMs “word” for each letter in the plaintext word. If there is more space on the line for the next plaintext word, the scribe writes down the code for space, and then the codes for the letters in the next word. Long spaces are written by writing the code for space more than once … The next line is used for the next word, and so on.
On the next folio, a different table may be used.
It’s hard to imagine the justification for such a scheme, but it does appear (at least initially) to fit some of the features of the VMs script (especially the repeating VMs words often seen).
I made a quick test that looks at VMs word frequencies on a single folio (in the Recipes section, which has the densest text). These showed a word frequency distribution that looks similar to the letter frequency distribution in Latin, apart from the most frequently occurring word (which is much more frequent) and which it is suggested would code for a space in the cipher.
However, on a typical folio, there are usually many more VMs words than there are plaintext letters. So the scheme has to be extended to allow the scribe a choice between several different VMs words to encode a single letter. Each table must have a set of words appearing in each plaintext letter column. Something like this:
| Plaintext | (space) | a | b | … |
| VMs words | 8am ay okoe | 4ohoe 2ay 1coe | faiis 4ay oka | … |
If this is indeed the scheme, one would expect to see patterns in the VMs word sequences that match patterns seen in the letter sequences of e.g. Latin words. Also, as Philip Neal pointed out, patterns like “word1 word2 word2 word1” would indicate a plaintext letter sequence of either “vowel consonant consonant vowel” or vice versa.
Looking through the whole of the VMs for sequence patterns (on the same line of text), I found the following:
- There are no 4 word sequences that repeat at all
- There are only four 3 word sequences that repeat, and each only twice
- There are no sequences at all of the form “xyyx”
(all of which I find rather surprising, and thought provoking).
So it looks like this hypothesis is dead in the water, and can be ticked off that long list of “things it might have been but in fact don’t fit”!
(It turns out that Elmar Vogt has been working on a related, but more sophisticated, idea which he describes on his blog and is called a “Stroke Theory”.)
The Cipher Black Box

This is how the cipher works: a plaintext is fed in to the “Black Box” and, based on a set of unknown parameters P, is enciphered by an unknown process in the box into the ciphertext, which is written onto the folio.
The internal mechanism of the Black Box is unknown. The only information we have is the output ciphertext (but we have a lot of it).
What strategies can we employ to discover how the internal mechanism of the Black Box works? What are the input parameters to the cipher? Can we avoid having to find out about the mechanism, and directly reverse the cipher, so yielding the plaintext from the ciphertext?
If we could “prod” the Box as enciphering was taking place (e.g. by twiddling one of the input parameters Pi), then by observing the output ciphertext, we could start to build a theory about how the cipher works.
Suppose we devise a candidate cipher that, from a sequence of random plaintext letters, and using a set of parameters we choose, generates a chosen line of VMs text exactly. Mathematically:
ciphertext = C(plaintext,P0…Pi)
where C is the cipher function. We can surely find a function that satisfies these conditions: some sort of State Machine is perhaps most appropriate. When twiddling one of the parameters Pi, and measuring the change in the ciphertext, we are able to calculate the partial derivative of C with respect to Pi:
δC/δPi = Δ(ciphertext)
If the variation on the ciphertext produces new ciphertext that is compatible with the rest of the ciphertext in the VMs, then this would suggest that Pi is a good parameter (i.e. that it is a candidate for retention in the candidate cipher). If, on the other hand, the variation produces invalid new ciphertext, the parameter is poor, and is a candidate for removal from the candidate cipher.
Potential algorithm:
- Create a state machine containing a cipher C that takes (many) Parameters P
- The state machine parameters are adjusted so that a (random) plaintext input string produces a valid sequence of VMs ciphertext
- Each parameter is varied slightly in value, and the state machine asked to reprocess the plaintext to produce new ciphertext
- The similarity of the new ciphertext is compared with the VMs corpus
- The parameter in question is demoted or promoted in weight
- Once the effects of all parameters have been examined they are graded by weight
- Good parameters are kept, poor ones discarded
- Develop an overall score for the state machine, based on a suitable metric
- Memorize this state machine if it has the best score so far
- Go to step 1, but now with the reduced set of parameters
This process is repeated for many different trial state machines, and the best memorized.
Inverting the Cipher
TBA
Strong’s Cipher
Strong’s “peculiar system of a double reversed arithmetic progression of a multiple alphabet” is a puzzling description, but GC recently (Feb 2010) explained it as “”double reversed arithmetic progression” as defined by the string 1-3-5-7-9-7-5-3-1-4-7-4″ (although I think the sequence given is an example, rather than the definition). The number of alphabets is “a handful”.
If we suppose that the cipher is indeed constructed like this, then can we crack it computationally?
First we need to make some assumptions. Let’s generously assume that the number of alphabets is 10. Let’s then assume that these alphabets are rotated through in a sequence that is 17 long (the number 17 is picked since it crops up as a feature of the VMs text in many places). Let’s not assume that the sequence is double, or reversed, or anything else: it’s just a sequence of alphabet numbers. Let’s assume that each alphabet contains 21 characters: abcdefghilmnopqrstuvx
We then take a sample of VMs text (I chose the first “paragraph” of f1v)
h1s9 1o8am oe oek1c9 1ay Fax ap 9kcc9 1ay oy o19 81o eho89 oho8ay 1o89 8o H9 HoH9 29 8h2ii9 K9 hok1o89 8ae 8oe 1ohco 8aiy 8ap so1c9 1o ho89
and, equipped with a large dictionary of Latin words, we start to build a possible cipher. To do this, we start by looking at the first VMs word “h1s9”, and pick a Latin word of the same length, at random: “acri”. With this pair we can start to construct the cipher table:
Voynich o 9 e 1 8 a h y c k 2 i K s m H p F x g & Alphabet 0 . . . . . . a . . . . . . . . . . . . . . Alphabet 1 . . . c . . . . . . . . . . . . . . . . . Alphabet 2 . . . . . . . . . . . . . r . . . . . . . Alphabet 3 . i . . . . . . . . . . . . . . . . . . . Alphabet 4 . . . . . . . . . . . . . . . . . . . . . Alphabet 5 . . . . . . . . . . . . . . . . . . . . . Alphabet 6 . . . . . . . . . . . . . . . . . . . . . Alphabet 7 . . . . . . . . . . . . . . . . . . . . . Alphabet 8 . . . . . . . . . . . . . . . . . . . . . Alphabet 9 . . . . . . . . . . . . . . . . . . . . .
We continue with the next word: “1o8am” and a random Latin word of the same length: “paveo”, and update the table:
Voynich o 9 e 1 8 a h y c k 2 i K s m H p F x g & Alphabet 0 . . . . . . a . . . . . . . . . . . . . . Alphabet 1 . . . c . . . . . . . . . . . . . . . . . Alphabet 2 . . . . . . . . . . . . . r . . . . . . . Alphabet 3 . i . . . . . . . . . . . . . . . . . . . Alphabet 4 . . . p . . . . . . . . . . . . . . . . . Alphabet 5 a . . . . . . . . . . . . . . . . . . . . Alphabet 6 . . . . v . . . . . . . . . . . . . . . . Alphabet 7 . . . . . e . . . . . . . . . . . . . . . Alphabet 8 . . . . . . . . . . . . . . o . . . . . . Alphabet 9 . . . . . . . . . . . . . . . . . . . . .
The next word is “eo” and the random Latin word is “do”. Now the Latin letter “o” has to be placed under the Voynich “o” column in Alphabet 0:
Voynich o 9 e 1 8 a h y c k 2 i K s m H p F x g & Alphabet 0 . . o . . . a . . . . . . . . . . . . . . Alphabet 1 . . . c . . . . . . . . . . . . . . . . . Alphabet 2 . . . . . . . . . . . . . r . . . . . . . Alphabet 3 . i . . . . . . . . . . . . . . . . . . . Alphabet 4 . . . p . . . . . . . . . . . . . . . . . Alphabet 5 a . . . . . . . . . . . . . . . . . . . . Alphabet 6 . . . . v . . . . . . . . . . . . . . . . Alphabet 7 . . . . . e . . . . . . . . . . . . . . . Alphabet 8 . . . . . . . . . . . . . . o . . . . . . Alphabet 9 d . . . . . . . . . . . . . . . . . . . .
We continue in this vein, picking random Latin words to match the VMs words, and attempting to place them into the cipher. This starts off easily, but rapidly becomes impossible, with the Latin words chosen: when we come to place a letter into the required column at the current alphabet in the sequence, we find that the position is already occupied by a different letter, or that the alphabet already contains that letter but in a different column.
In such cases we try to select a different Latin word to see if it will fit. If we exhaust all possible Latin words, then we backtrack to the beginning, and start afresh with a new sequence and new choices.
Most of the time, this algorithm doesn’t get further than a few words into the text before failing. Occasionally it gets quite a long way. Of course, the search space of possible Latin word combinations is staggering …
This is one of the more interesting attempts at deciphering f2v:
Voynich o 9 e 1 8 a h y c k 2 i K s m H p F x g & Alphabet 0 l . t a s . b o f . n . . . . . . . . . . Alphabet 1 m i . o l b . . r . . t . . . g . . . . . Alphabet 2 f a u e . . . s . . . i . n . . . . . . . Alphabet 3 . o . v f . i . . n u . . . . . . e . . . Alphabet 4 . a . h d i . . . . . . o . . . . . . . . Alphabet 5 e s . i t o . . . . . . . . . . . . a . . Alphabet 6 u . . . r s c . . . . . . . . . . . . . . Alphabet 7 u . i . n b . s r . . . . . . m t . . . . Alphabet 8 e i . . . d u . . c . . . . a . . . . . . Alphabet 9 s . . u . . . . . n . . . . . a . . . . . Sequence vals = 0 1 2 3 4 5 6 7 8 9 0 1 2 3 5 7 8
h1s9 1o8am oe oek1c9 1ay Fax ap 9kcc9 1ay oy o19 81o eho89 oho8ay 1o89 8o H9 HoH9 29 8h2ii9 K9 hok1o89 8ae 8oe 1ohco 8aiy 8ap so1c9 1o ho89 bono herba st muniri abs eia st infra vos eo meo diu iussi fiendo offa tu mi alga us nuntio os cuculla
Are the words in the Voynich Manuscript phonetic codes?
A good question, to which the answer is probably “no”. But, like most questions that the Voynich provokes, it’s fun to try to answer. I’ve detailed the approach and result on my web site.

The procedure is to take each word in a body of plaintext and convert it to a phonetic code using the Soundex and Double Metaphone algorithms. Then accumulate the frequency distribution of the phonetic codes in the plaintext and compare with the frequency distribution of word counts in the VMs. If the VMs “words” are phonetic abbreviations of plaintext words, then one might expect the frequency distributions to match in form and level.
(Of course, Soundex is designed for English, so may not make much practical sense when applied to other languages. However, it is one means of expressing phonetic content: and thus allows us to generate a phonetic description for any foreign language word, albeit in an English pronounciation! Double Metaphone is designed for several different languages.)
Example Soundex
To illustrate the Soundex compression, here is a Latin phrase and its Soundex equivalent:
et post non multas elapsi temporis horas
E300 P230 N500 M432 E412 T516 H620
See below for the Soundex results
(there are a total of 26×666 = 17316 Soundex codes possible i.e. A000 … Z666)
Example Double Metaphone
With the Double Metaphone encoding, the nice feature is that the encoded words look a little like the plaintext word, so you get a better feel for what is seen.
For example:
Plain: The quick brown fox jumps over the lazy dog
Soundex: T000 Q200 B650 F200 J512 O160 T000 L200 D200
Dbl.Meta: 0 KK PRN FKS JMPS AFR 0 LS DK
Also, one is able to specify a maximum encoding length, so that longer words like “manuscript” come out as “MNSKPT” in Double Metaphone, rather than the “M526” you would get in Soundex.
Producing the word frequency tables using Double Metaphone (comparing the Herbal Folios with a Latin text describing a herb garden)
8am 0.038182747 AT 0.029438822 e.g "et" 1oe 0.020316487 S 0.014719411 "se" 1oy 0.014599285 HK 0.01425943 "huc" s 0.011638591 K 0.012419503 "quo" oy 0.010107198 AN 0.012419503 "in" 19 0.010107198 TM 0.00873965 "tum" am 0.009596733 NN 0.008279668 "non" 8ay 0.00949464 KM 0.008279668 "quam" 89 0.0089841755 KT 0.006439742 "quot" K9 0.008882083 FRT 0.0059797605 "forti" (numbers are the relative frequencies) Compare with Soundex: 8am 0.038182747 E300 0.021619136 1oe 0.020316487 H200 0.019319227 1oy 0.014599285 S000 0.014719411 s 0.011638591 I500 0.013339466 oy 0.010107198 Q000 0.01149954 19 0.010107198 N500 0.008279668 am 0.009596733 Q200 0.006439742 8ay 0.00949464 Q300 0.006439742 89 0.0089841755 V620 0.0059797605 K9 0.008882083 D500 0.0059797605
The phonetic distribution is *very* sensitive to what is used for the plaintext, (surprisingly?) which makes it unreasonable to draw any conclusions by comparison to the VMs.
Comparison Tables: Soundex
Herbal Folios
Augustinus (Latin): Top 40 words in source and target Source Target ------ ------ 8am 0.038182747 E300 0.064491205 1oe 0.020316487 N500 0.026331432 1oy 0.014599285 M000 0.025974799 s 0.011638591 I500 0.025737043 oy 0.010107198 T000 0.02318117 19 0.010107198 Q000 0.021932954 am 0.009596733 E200 0.02044698 8ay 0.00949464 E230 0.013789824 89 0.0089841755 A300 0.012719925 K9 0.008882083 Q300 0.012719925 2oe 0.0077590607 S300 0.011174513 8an 0.0073506893 N200 0.010639563 1c9 0.0071465033 I400 0.009807418 oe 0.006738132 S000 0.008737518 ay 0.006636039 U300 0.008321445 2o 0.006533946 C500 0.00808369 oham 0.005104645 E550 0.007964812 oh9 0.0047983667 H200 0.007964812 4ok19 0.0047983667 D200 0.00754874 9 0.0046962737 D000 0.0067760344 8ae 0.0044920878 Q200 0.0067760344 2oy 0.004389995 P600 0.0065977178 Koe 0.004287902 Q500 0.00647884 4oh19 0.004287902 M200 0.005884451 7am 0.0041858093 S500 0.0057061343 Koy 0.0040837163 A000 0.0055278176 8oy 0.0039816233 A320 0.005171184 29 0.0039816233 I120 0.0048145507 1H9 0.0039816233 E000 0.0045173564 ok9 0.0039816233 E630 0.0042796005 1o 0.0038795304 I300 0.0041607227 8oe 0.0034711587 D550 0.003982406 1o89 0.003369066 A350 0.0039229672 ohae 0.003369066 E350 0.0039229672 1am 0.003266973 T550 0.0038635284 1c79 0.003266973 A550 0.0038635284 y 0.00316488 S530 0.003625773 1ay 0.0029606943 M500 0.003566334 okoe 0.0028586013 S200 0.0033285783 sam 0.0028586013 E500 0.0032097006 Latin Herb Garden (Latin): Top 40 words in source and target Source Target ------ ------ 8am 0.038182747 E300 0.021619136 1oe 0.020316487 H200 0.019319227 1oy 0.014599285 S000 0.014719411 s 0.011638591 I500 0.013339466 oy 0.010107198 Q000 0.01149954 19 0.010107198 N500 0.008279668 am 0.009596733 Q200 0.006439742 8ay 0.00949464 Q300 0.006439742 89 0.0089841755 V620 0.0059797605 K9 0.008882083 D500 0.0059797605 2oe 0.0077590607 P600 0.0059797605 8an 0.0073506893 P632 0.0059797605 1c9 0.0071465033 F630 0.005519779 oe 0.006738132 I400 0.0050597973 ay 0.006636039 N200 0.0050597973 2o 0.006533946 I536 0.0050597973 oham 0.005104645 Q500 0.0050597973 oh9 0.0047983667 C616 0.0045998157 4ok19 0.0047983667 N550 0.0045998157 9 0.0046962737 S100 0.0045998157 8ae 0.0044920878 S300 0.0045998157 2oy 0.004389995 E230 0.004139834 Koe 0.004287902 O360 0.004139834 4oh19 0.004287902 C523 0.004139834 7am 0.0041858093 V400 0.004139834 Koy 0.0040837163 C500 0.004139834 8oy 0.0039816233 T500 0.004139834 29 0.0039816233 L300 0.004139834 1H9 0.0039816233 F653 0.0036798527 ok9 0.0039816233 U300 0.0036798527 1o 0.0038795304 A300 0.0036798527 8oe 0.0034711587 G520 0.0036798527 1o89 0.003369066 T100 0.0036798527 ohae 0.003369066 N236 0.0036798527 1am 0.003266973 S200 0.0036798527 1c79 0.003266973 I525 0.0036798527 y 0.00316488 S162 0.003219871 1ay 0.0029606943 T550 0.003219871 okoe 0.0028586013 V536 0.003219871 sam 0.0028586013 V633 0.003219871
Culpeper (Old English): Top 40 words in source and target Source Target ------ ------ 8am 0.038182747 T000 0.10639342 1oe 0.020316487 A530 0.054539897 1oy 0.014599285 O100 0.035268757 s 0.011638591 I500 0.024507163 oy 0.010107198 O600 0.018764427 19 0.010107198 I300 0.017799262 am 0.009596733 A000 0.017147776 8ay 0.00949464 I200 0.01615848 89 0.0089841755 W300 0.013842083 K9 0.008882083 T500 0.01140504 2oe 0.0077590607 B000 0.010568563 8an 0.0073506893 T200 0.010464003 1c9 0.0071465033 S300 0.0094907945 oe 0.006738132 F600 0.009394278 ay 0.006636039 B300 0.008783007 2o 0.006533946 T300 0.008533672 oham 0.005104645 A200 0.00839694 oh9 0.0047983667 A600 0.007793712 4ok19 0.0047983667 W200 0.0068124603 9 0.0046962737 H300 0.00673203 8ae 0.0044920878 L120 0.0065068244 2oy 0.004389995 S500 0.0060081556 Koe 0.004287902 A500 0.005895553 4oh19 0.004287902 A420 0.005662305 7am 0.0041858093 A400 0.00551753 Koy 0.0040837163 B520 0.005356669 8oy 0.0039816233 T600 0.005348626 29 0.0039816233 O500 0.0049706027 1H9 0.0039816233 G300 0.004874086 ok9 0.0039816233 M500 0.0047856127 1o 0.0038795304 H610 0.004624752 8oe 0.0034711587 L200 0.0045764935 1o89 0.003369066 W400 0.0041019535 ohae 0.003369066 B430 0.0040536956 1am 0.003266973 A300 0.0040295664 1c79 0.003266973 R300 0.003965222 y 0.00316488 M300 0.0039089206 1ay 0.0029606943 S540 0.0039008774 okoe 0.0028586013 S000 0.003836533 sam 0.0028586013 P420 0.003820447 German Cook Book 1553 (Old German): Top 40 words in source and target Source Target ------ ------ 8am 0.038182747 V530 0.06859404 1oe 0.020316487 A500 0.06320765 1oy 0.014599285 J500 0.030449597 s 0.011638591 D200 0.026547212 oy 0.010107198 S000 0.026437286 19 0.010107198 D000 0.02423876 am 0.009596733 D500 0.01802792 8ay 0.00949464 D650 0.01593932 89 0.0089841755 D652 0.014949983 K9 0.008882083 E200 0.014345388 2oe 0.0077590607 N500 0.01264153 8an 0.0073506893 Z000 0.011542266 1c9 0.0071465033 L200 0.0113773765 oe 0.006738132 W400 0.01038804 ay 0.006636039 M200 0.010278113 2o 0.006533946 T000 0.009948335 oham 0.005104645 M300 0.009563592 oh9 0.0047983667 W500 0.008849071 4ok19 0.0047983667 T200 0.0087941075 9 0.0046962737 M250 0.008739145 8ae 0.0044920878 A100 0.008244476 2oy 0.004389995 A550 0.0081345495 Koe 0.004287902 V500 0.008024624 4oh19 0.004287902 J300 0.0078047705 7am 0.0041858093 A420 0.0077498076 Koy 0.0040837163 A200 0.007694844 8oy 0.0039816233 S350 0.007255139 29 0.0039816233 W520 0.007255139 1H9 0.0039816233 D600 0.0071452125 ok9 0.0039816233 W000 0.006650544 1o 0.0038795304 N300 0.006430691 8oe 0.0034711587 Z260 0.006375728 1o89 0.003369066 O360 0.006265802 ohae 0.003369066 M500 0.006265802 1am 0.003266973 N513 0.0058260965 1c79 0.003266973 G300 0.00571617 y 0.00316488 B200 0.0054963175 1ay 0.0029606943 W630 0.0054963175 okoe 0.0028586013 S432 0.005386391 sam 0.0028586013 W430 0.005386391 Thomas Hardy (English): Top 40 words in source and target Source Target ------ ------ 8am 0.038182747 T000 0.093254805 1oe 0.020316487 A000 0.036285233 1oy 0.014599285 A530 0.030430516 s 0.011638591 O100 0.029694293 oy 0.010107198 S000 0.02099986 19 0.010107198 W200 0.019352125 am 0.009596733 I500 0.01731875 8ay 0.00949464 H000 0.014128454 89 0.0089841755 I000 0.013357174 K9 0.008882083 B000 0.012235311 2oe 0.0077590607 H200 0.01167438 8an 0.0073506893 S300 0.011428973 1c9 0.0071465033 W300 0.011393914 oe 0.006738132 T300 0.010517459 ay 0.006636039 A200 0.010236993 2o 0.006533946 H600 0.010131819 oham 0.005104645 H300 0.009956528 oh9 0.0047983667 F600 0.009465713 4ok19 0.0047983667 I300 0.009430655 9 0.0046962737 T200 0.009255365 8ae 0.0044920878 Y000 0.009255365 2oy 0.004389995 O500 0.008974899 Koe 0.004287902 T500 0.008063385 4oh19 0.004287902 M500 0.0076426873 7am 0.0041858093 A300 0.007081756 Koy 0.0040837163 N000 0.006976581 8oy 0.0039816233 M000 0.006731174 29 0.0039816233 B300 0.006625999 1H9 0.0039816233 T600 0.006590941 ok9 0.0039816233 A500 0.0063455338 1o 0.0038795304 F650 0.005994952 8oe 0.0034711587 W600 0.005539195 1o89 0.003369066 W000 0.005188613 ohae 0.003369066 N300 0.0050834385 1am 0.003266973 W400 0.0049081477 1c79 0.003266973 O200 0.0048380313 y 0.00316488 I200 0.0048380313 1ay 0.0029606943 H100 0.0048380313 okoe 0.0028586013 S500 0.0047328565 sam 0.0028586013 G164 0.004592624 Spanish 1543 (Spanish): Top 40 words in source and target Source Target ------ ------ 8am 0.038182747 T000 0.05038168 1oe 0.020316487 Q000 0.044711012 1oy 0.014599285 N000 0.044274807 s 0.011638591 D000 0.03838604 oy 0.010107198 Y000 0.036423117 19 0.010107198 L000 0.03598691 am 0.009596733 S000 0.02791712 8ay 0.00949464 E500 0.021374045 89 0.0089841755 H200 0.020719739 K9 0.008882083 A000 0.018974917 2oe 0.0077590607 E400 0.017230097 8an 0.0073506893 L200 0.016793894 1c9 0.0071465033 P600 0.016575791 oe 0.006738132 C500 0.015485277 ay 0.006636039 B500 0.014176663 2o 0.006533946 M200 0.01308615 oham 0.005104645 C000 0.01308615 oh9 0.0047983667 Q620 0.012868048 4ok19 0.0047983667 E200 0.011123228 9 0.0046962737 S200 0.009378408 8ae 0.0044920878 D120 0.009378408 2oy 0.004389995 M000 0.0082878955 Koe 0.004287902 H516 0.008069793 4oh19 0.004287902 P620 0.007197383 7am 0.0041858093 D200 0.0063249725 Koy 0.0040837163 S500 0.0061068702 8oy 0.0039816233 G650 0.0056706653 29 0.0039816233 Q530 0.0054525626 1H9 0.0039816233 S516 0.0054525626 ok9 0.0039816233 A520 0.0052344603 1o 0.0038795304 M260 0.0050163576 8oe 0.0034711587 M400 0.0050163576 1o89 0.003369066 C200 0.0050163576 ohae 0.003369066 D400 0.004798255 1am 0.003266973 S600 0.004798255 1c79 0.003266973 T300 0.004798255 y 0.00316488 A400 0.0045801527 1ay 0.0029606943 P300 0.0045801527 okoe 0.0028586013 P360 0.00436205 sam 0.0028586013 S160 0.00436205 French 1367 (Mediaeval French): Top 40 words in source and target Source Target ------ ------ 8am 0.038182747 L000 0.05783751 1oe 0.020316487 D000 0.05557233 1oy 0.014599285 E300 0.049682874 s 0.011638591 Q000 0.030806402 oy 0.010107198 A000 0.025218965 19 0.010107198 P600 0.025218965 am 0.009596733 L200 0.024161883 8ay 0.00949464 E500 0.022802778 89 0.0089841755 O000 0.018272424 K9 0.008882083 S300 0.017366353 2oe 0.0077590607 &000 0.015252189 8an 0.0073506893 S530 0.014799153 1c9 0.0071465033 R000 0.0135910595 oe 0.006738132 N000 0.0135910595 ay 0.006636039 S000 0.011476895 2o 0.006533946 L600 0.0110238595 oham 0.005104645 N400 0.009664753 oh9 0.0047983667 S256 0.009513741 4ok19 0.0047983667 E524 0.009211718 9 0.0046962737 C000 0.009211718 8ae 0.0044920878 P625 0.009060706 2oy 0.004389995 D300 0.0084566595 Koe 0.004287902 D200 0.008003624 4oh19 0.004287902 C200 0.008003624 7am 0.0041858093 D320 0.008003624 Koy 0.0040837163 N236 0.007852612 8oy 0.0039816233 E230 0.0070975535 29 0.0039816233 C500 0.0057384474 1H9 0.0039816233 O635 0.0057384474 ok9 0.0039816233 P200 0.0057384474 1o 0.0038795304 T600 0.0054364237 8oe 0.0034711587 I620 0.0051344004 1o89 0.003369066 I350 0.0051344004 ohae 0.003369066 V253 0.0049833884 1am 0.003266973 S600 0.0048323767 1c79 0.003266973 F652 0.004681365 y 0.00316488 T520 0.004681365 1ay 0.0029606943 F600 0.004530353 okoe 0.0028586013 G600 0.0043793414 sam 0.0028586013 E200 0.0040773177 Flores Filosofia (Mediaeval Spanish): Top 40 words in source and target Source Target ------ ------ 8am 0.038182747 Q000 0.07295496 1oe 0.020316487 E000 0.069623165 1oy 0.014599285 L000 0.04779412 s 0.011638591 E400 0.03952206 oy 0.010107198 S000 0.037798714 19 0.010107198 E200 0.030101104 am 0.009596733 D000 0.026424633 8ay 0.00949464 N500 0.02366728 89 0.0089841755 C500 0.017922794 K9 0.008882083 P600 0.017233456 2oe 0.0077590607 L200 0.017118566 8an 0.0073506893 D400 0.015165442 1c9 0.0071465033 B500 0.014246323 oe 0.006738132 E500 0.013901655 ay 0.006636039 O500 0.013556985 2o 0.006533946 D200 0.013212317 oham 0.005104645 C000 0.012293198 oh9 0.0047983667 M200 0.010914522 4ok19 0.0047983667 P200 0.009995405 9 0.0046962737 H000 0.008157169 8ae 0.0044920878 S130 0.00804228 2oy 0.004389995 F200 0.007582721 Koe 0.004287902 S200 0.007467831 4oh19 0.004287902 M260 0.007467831 7am 0.0041858093 A400 0.0065487134 Koy 0.0040837163 M400 0.0064338236 8oy 0.0039816233 S500 0.006204044 29 0.0039816233 Q530 0.0060891546 1H9 0.0039816233 S600 0.005974265 ok9 0.0039816233 C220 0.005859375 1o 0.0038795304 S160 0.005514706 8oe 0.0034711587 E530 0.0051700366 1o89 0.003369066 T000 0.0051700366 ohae 0.003369066 F260 0.0051700366 1am 0.003266973 A200 0.0048253676 1c79 0.003266973 A420 0.0048253676 y 0.00316488 R000 0.0045955884 1ay 0.0029606943 D420 0.004365809 okoe 0.0028586013 M530 0.004250919 sam 0.0028586013 V500 0.004250919 Vietnamese Bible (Vietnamese): Top 40 words in source and target Source Target ------ ------ 8am 0.038182747 N200 0.107542574 1oe 0.020316487 C000 0.09951338 1oy 0.014599285 I000 0.08856448 s 0.011638591 T000 0.086618006 oy 0.010107198 N000 0.083211675 19 0.010107198 V000 0.045012165 am 0.009596733 S000 0.042092457 8ay 0.00949464 L000 0.034793187 89 0.0089841755 H000 0.034306567 K9 0.008882083 M000 0.029927006 2oe 0.0077590607 G000 0.023357663 8an 0.0073506893 A000 0.020924574 1c9 0.0071465033 Y000 0.019708028 oe 0.006738132 K000 0.01922141 ay 0.006636039 U000 0.016301703 2o 0.006533946 L500 0.016058395 oham 0.005104645 P000 0.015815085 oh9 0.0047983667 B000 0.015815085 4ok19 0.0047983667 C520 0.01459854 9 0.0046962737 T600 0.0124087585 8ae 0.0044920878 R000 0.01216545 2oy 0.004389995 C200 0.011435523 Koe 0.004287902 ╨000 0.011192214 4oh19 0.004287902 D000 0.011192214 7am 0.0041858093 K520 0.010948905 Koy 0.0040837163 B500 0.009489051 8oy 0.0039816233 M500 0.008029197 29 0.0039816233 ├000 0.007542579 1H9 0.0039816233 T652 0.005839416 ok9 0.0039816233 T500 0.005596107 1o 0.0038795304 C500 0.005596107 8oe 0.0034711587 D500 0.005109489 1o89 0.003369066 L520 0.004379562 ohae 0.003369066 N500 0.004379562 1am 0.003266973 X000 0.003892944 1c79 0.003266973 ╙000 0.003649635 y 0.00316488 T650 0.003649635 1ay 0.0029606943 P500 0.003649635 okoe 0.0028586013 ┴200 0.003406326 sam 0.0028586013 D520 0.002676399
Book of the Courtier 1561 (Mediaeval English): Top 40 words in source and target Source Target ------ ------ 8am 0.038182747 T000 0.08259616 1oe 0.020316487 A530 0.04111586 1oy 0.014599285 O100 0.03379386 s 0.011638591 I500 0.02981811 oy 0.010107198 T300 0.026770037 19 0.010107198 A000 0.022396713 am 0.009596733 B000 0.015902992 8ay 0.00949464 T500 0.015306629 89 0.0089841755 S000 0.01424643 K9 0.008882083 M500 0.013948249 2oe 0.0077590607 I300 0.013948249 8an 0.0073506893 T200 0.013517543 1c9 0.0071465033 H000 0.013086837 oe 0.006738132 N300 0.012755524 ay 0.006636039 W300 0.012324818 2o 0.006533946 F600 0.012291688 oham 0.005104645 W200 0.0120929 oh9 0.0047983667 I000 0.011132094 4ok19 0.0047983667 I200 0.010535732 9 0.0046962737 B300 0.010138158 8ae 0.0044920878 M000 0.009475533 2oy 0.004389995 A200 0.009077958 Koe 0.004287902 H100 0.008216546 4oh19 0.004287902 H200 0.007918364 7am 0.0041858093 T520 0.0077195773 Koy 0.0040837163 A500 0.007388265 8oy 0.0039816233 W400 0.0072888713 29 0.0039816233 A400 0.0070569525 1H9 0.0039816233 Y000 0.0070238216 ok9 0.0039816233 O360 0.0067587714 1o 0.0038795304 H300 0.0063611967 8oe 0.0034711587 T600 0.006096147 1o89 0.003369066 H500 0.0060630157 ohae 0.003369066 O600 0.005930491 1am 0.003266973 W600 0.005864228 1c79 0.003266973 M230 0.0054666535 y 0.00316488 W000 0.0054666535 1ay 0.0029606943 M200 0.005135341 okoe 0.0028586013 S300 0.0050359475 sam 0.0028586013 S500 0.004969685
Recipes Folios
The Recipes section with the Latin Herb Garden: Top 40 words in source and target Source Target ------ ------ am 0.018943263 E300 0.021619136 ay 0.014393166 H200 0.019319227 ae 0.0136502925 S000 0.014719411 1c89 0.012257406 I500 0.013339466 4ohC9 0.01179311 Q000 0.01149954 1c9 0.010493082 N500 0.008279668 oe 0.010400223 Q200 0.006439742 4oham 0.010307364 Q300 0.006439742 8am 0.009843068 V620 0.0059797605 4ohan 0.009564491 D500 0.0059797605 oham 0.007800167 P600 0.0059797605 okam 0.0070572942 P632 0.0059797605 oy 0.006314421 F630 0.005519779 an 0.0058501256 I400 0.0050597973 ohan 0.0058501256 N200 0.0050597973 e 0.0058501256 I536 0.0050597973 2c89 0.005757266 Q500 0.0050597973 1c79 0.0056644073 C616 0.0045998157 ohC9 0.0056644073 N550 0.0045998157 okay 0.0052929707 S100 0.0045998157 1oe 0.0052929707 S300 0.0045998157 2c9 0.0051072524 E230 0.004139834 okae 0.004921534 O360 0.004139834 4ohC89 0.004921534 C523 0.004139834 okan 0.0048286747 V400 0.004139834 1coe 0.004735816 C500 0.004139834 1C9 0.0042715203 T500 0.004139834 ohae 0.004085802 L300 0.004139834 8an 0.0039929426 F653 0.0036798527 4okam 0.0038072243 U300 0.0036798527 8ay 0.0036215063 A300 0.0036798527 4ohay 0.0036215063 G520 0.0036798527 1co 0.0036215063 T100 0.0036798527 4ohae 0.0035286471 N236 0.0036798527 okC9 0.0035286471 S200 0.0036798527 4ohc9 0.003435788 I525 0.0036798527 eham 0.003435788 S162 0.003219871 9 0.003435788 T550 0.003219871 okc89 0.003435788 V536 0.003219871 y 0.0033429288 V633 0.003219871
Astrological Folios
The Astrological section with the Latin Herb Garden: Top 40 words in source and target Source Target ------ ------ ay 0.016070843 E300 0.021619136 am 0.011479174 H200 0.019319227 ae 0.009839292 S000 0.014719411 8am 0.008527386 I500 0.013339466 s 0.007543457 Q000 0.01149954 8ay 0.007215481 N500 0.008279668 8ae 0.006559528 Q200 0.006439742 89 0.0062315515 Q300 0.006439742 okc9 0.0062315515 V620 0.0059797605 okcos 0.005903575 D500 0.0059797605 okC9 0.005903575 P600 0.0059797605 ohC9 0.0055755987 P632 0.0059797605 okay 0.0052476223 F630 0.005519779 1c9 0.0052476223 I400 0.0050597973 okam 0.004919646 N200 0.0050597973 okcc9 0.004919646 I536 0.0050597973 ok9 0.0045916694 Q500 0.0050597973 ap 0.0045916694 C616 0.0045998157 o 0.0045916694 N550 0.0045998157 okco89 0.0045916694 S100 0.0045998157 oe 0.004263693 S300 0.0045998157 1oe 0.004263693 E230 0.004139834 okae 0.0039357166 O360 0.004139834 2c9 0.0039357166 C523 0.004139834 1coy 0.0039357166 V400 0.004139834 ohae 0.0039357166 C500 0.004139834 9 0.0036077404 T500 0.004139834 say 0.0036077404 L300 0.004139834 19 0.0036077404 F653 0.0036798527 ohay 0.0036077404 U300 0.0036798527 oy 0.003279764 A300 0.0036798527 7ay 0.003279764 G520 0.0036798527 1ch9 0.003279764 T100 0.0036798527 oham 0.003279764 N236 0.0036798527 ohcos 0.003279764 S200 0.0036798527 1co89 0.0029517876 I525 0.0036798527 okoe 0.0029517876 S162 0.003219871 ae9 0.0029517876 T550 0.003219871 ohcoe 0.0026238111 V536 0.003219871 2oe 0.0026238111 V633 0.003219871
Biological Folios
The Biological section with the Latin Herb Garden: Top 40 words in source and target Source Target ------ ------ oe 0.03410959 E300 0.021619136 4ohan 0.021643836 H200 0.019319227 1c89 0.02109589 S000 0.014719411 2c89 0.015616438 I500 0.013339466 4ohc89 0.015479452 Q000 0.01149954 4oe 0.015342466 N500 0.008279668 4ohae 0.014109589 Q200 0.006439742 1c9 0.013287671 Q300 0.006439742 4oham 0.011506849 V620 0.0059797605 4ohC89 0.0113698635 D500 0.0059797605 8am 0.010410959 P600 0.0059797605 oy 0.010136986 P632 0.0059797605 4ohC9 0.009589042 F630 0.005519779 8ay 0.009178082 I400 0.0050597973 2c9 0.009041096 N200 0.0050597973 4oh9 0.007945205 I536 0.0050597973 1c79 0.007671233 Q500 0.0050597973 8ae 0.007671233 C616 0.0045998157 am 0.007260274 N550 0.0045998157 4ohay 0.0064383564 S100 0.0045998157 y 0.00630137 S300 0.0045998157 8an 0.0060273972 E230 0.004139834 ohan 0.0060273972 O360 0.004139834 89 0.005890411 C523 0.004139834 4ohc79 0.0057534245 V400 0.004139834 1H9 0.0056164386 C500 0.004139834 4ohc9 0.005479452 T500 0.004139834 e1c89 0.005068493 L300 0.004139834 soe 0.005068493 F653 0.0036798527 4ohcc89 0.005068493 U300 0.0036798527 4okc89 0.005068493 A300 0.0036798527 okc89 0.0049315067 G520 0.0036798527 oham 0.004794521 T100 0.0036798527 2c79 0.004794521 N236 0.0036798527 s 0.0046575344 S200 0.0036798527 ay 0.004520548 I525 0.0036798527 sam 0.0043835617 S162 0.003219871 san 0.004109589 T550 0.003219871 oe9 0.0039726025 V536 0.003219871 5c89 0.0039726025 V633 0.003219871
Frequency Table for Plaintext Words
As a comparison, here is a frequency table for plaintext words in the “Latin Herb Garden” compared with the Herbal Folios
Top 40 words in source and target Source Target ------ ------ 8am 0.038182747 et 0.021159153 1oe 0.020316487 in 0.0096596135 1oy 0.014599285 si 0.0096596135 s 0.011638591 non 0.008279668 oy 0.010107198 quae 0.006899724 19 0.010107198 hoc 0.005519779 am 0.009596733 dum 0.0045998157 8ay 0.00949464 huius 0.004139834 89 0.0089841755 quam 0.004139834 K9 0.008882083 haec 0.004139834 2oe 0.0077590607 quod 0.0036798527 8an 0.0073506893 ut 0.0036798527 1c9 0.0071465033 per 0.0036798527 oe 0.006738132 tibi 0.0036798527 ay 0.006636039 cum 0.0036798527 2o 0.006533946 tum 0.0036798527 oham 0.005104645 tamen 0.003219871 oh9 0.0047983667 nec 0.003219871 4ok19 0.0047983667 forte 0.003219871 9 0.0046962737 est 0.003219871 8ae 0.0044920878 illa 0.0027598895 2oy 0.004389995 sub 0.0027598895 Koe 0.004287902 inter 0.0027598895 4oh19 0.004287902 vires 0.0027598895 7am 0.0041858093 genus 0.0027598895 Koy 0.0040837163 sed 0.0027598895 8oy 0.0039816233 lilia 0.0027598895 29 0.0039816233 quoque 0.0022999079 1H9 0.0039816233 se 0.0022999079 ok9 0.0039816233 iam 0.0022999079 1o 0.0038795304 undique 0.0022999079 8oe 0.0034711587 quis 0.0022999079 1o89 0.003369066 aut 0.0022999079 ohae 0.003369066 etiam 0.0022999079 1am 0.003266973 satis 0.0022999079 1c79 0.003266973 viscera 0.0022999079 y 0.00316488 odore 0.0022999079 1ay 0.0029606943 de 0.0022999079 okoe 0.0028586013 quo 0.0022999079 sam 0.0028586013 ore 0.0018399263
