Archive
Word Positions on the Folios – Part Deux
In the previous post, we looked at Voynich words that have a marked affinity for the first position in a line of text, with a restriction to words on the Currier B folios. Those words are:

In this post, we’ll look at the words that have an affinity for the ends of the text lines, and words that are disinclined to appear line initial or terminal.
For this, we introduce the metric that is the fractional position of the word in the text line. For the word at the start of the line, this metric is 0.0, and for the word at the end of the line it is 1.0, and for a word half way along the line it is 0.5. We can plot this metric for each word.
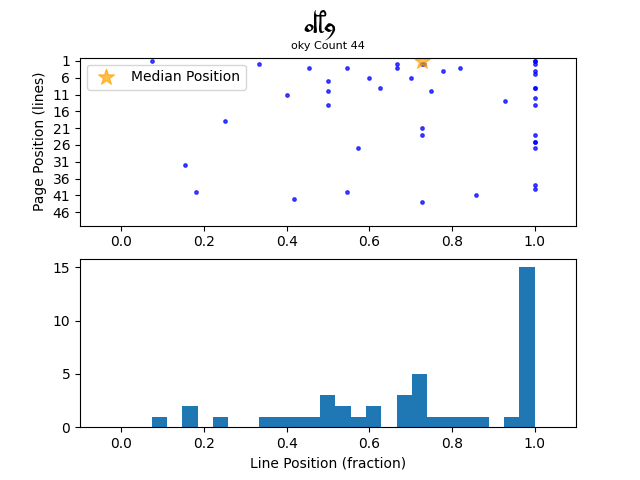
Firstly, let’s look at the word “daiin” with the metric:

The upper half of the Figure shows the page positions of all instances of “daiin”, with the fractional line positions on the x axis. The lower half shows a histogram of the fractional line positions. We can see what we observed in the first post, that “daiin” has a strong affinity for the first line position (fraction 0.0). But we also see that it sometimes appears as the last position in lines of text (fraction 1.0).
Looking at all the words, we can categorize them into six categories as follows:
- Words often in First Position – dai, daiin, dair, sai, saiin, sar, sol
- Words often in Last Position – am, dy, oky, oly, qoky
- Words never in First Position – ai, aiin, air, al, am, chcthy, chdy, checkhy, cheedy, cheky, cheody, chody, chy, dy, kai, kedy, keedy, okal, okedy, oky, oly, opchedy, otai, otal, otar, oty, raiin, shckhy
- Words never in Last Position – ai, cheo, dai, kai, kaiin, okai, otai, qokai, qokain, qotai, sai, shckhy, sheedy
- Words never in First or Last Position – ai, kai, otai, shckhy
- The rest – ar, chckhy, chedy, cheey, cheol, chey, chol, dal, dar, dol, kar, lchedy, lchey, lkaiin, okaiin, okar, okeedy, okeey, ol, or, otaiin, otedy, oteedy, oteey, qokaiin, qokal, qokar, qokchdy, qokedy, qokeedy, qokeey, qokey, qokol, qol, qotaiin, qotal, qotar, qotedy, qoteedy, qoty, shdy, shedy, sheey, sheol, shey, shol, tedy
Words often in Last Position





Words Never in First or Last Position





In the next post, we’ll look at possible explanations of these word positional data.
Cipher Wheels
Here is a set of three cipher wheels inspired by Rene’s recent arXiv paper, and based on Stolfi’s core-crust-mantle work.

These wheels can account for ~93% of all VMS words if you follow these rules:
- Select none or more glyphs from the outer ring
- Append none or one glyph from the middle Gallows ring
- Append none or more glyphs from the inner ring
(The outer ring is Stolfi Crust + Mantle + EVA aoye (17 glyphs), the middle ring is Stolfi Core (8 glyphs), the inner ring is Stolfi Crust + Mantle + EVA aoye (17 glyphs).)
I do like the number 17 as it jives with f57v.
Genetic Algorithm
Practically, it’s extremely doubtful that the above wheels were what was used to write the VMS! What seems more likely is that there were some number of wheels, N, and when a plaintext word was being enciphered only one glyph was used from each of the N wheels, in the style of the middle Gallows ring in the illustration above. What is also likely is that it wasn’t as simple as this, but it’s a good working hypothesis.
The EVA transcription’s VMS words are almost universally 10 glyphs or less long (Rene goes into detail about this in his paper), which suggests that N, the number of wheels, is at most 10. Each of the N wheels should have one or more glyphs around it, and when enciphering a word, the user may skip one or more of the N wheels (or each of the N wheels has a position for a null glyph: it amounts to the same thing).
The question then arises, what set of N glyph wheels is able to reproduce all the EVA words in the VMS, when only one glyph may be selected from each wheel?
This is an ideal task for a Genetic Algorithm! Specify a chromosome as having a number of wheels randomly selected between 3 and 10, and for each of those wheels assign between 4 and 24 glyphs (selected from all the VMS glyphs) at random to make up the wheel. Generate hundreds of such chromosomes as the initial population.
To evaluate the fitness of each chromosome, feed it each of the VMS words in turn, and decide whether the chromosome’s wheels can be used to recreate that word. In particular, score each chromosome taking into account:
- The number of VMS words it can successfully reproduce.
- The number of glyphs that need to be selected from each wheel before moving to the next wheel (lower is better, 1 is ideal, zero is also fine).
- The wheel sizes: chromosomes with wheels of all the same size score higher than those with widely different wheel sizes.
Armed with the fitness function, score each chromosome, order the population by decreasing fitness, discard the bottom half, generate new chromosomes by mating the top half, mutate some of them, re-score, rinse and repeat until the winning chromosome reveals the best N wheels for the problem.
Results will be forthcoming …!
Using t-distributed Stochastic Neighbor Embedding (TSNE) to cluster folios
For this attack we’ll use the Takeshi EVA transcription to count the number of times each glyph appears on each folio. This gives us a vector of probabilities for each glyph, for each folio – the vectors are 24 long, as there are 24 EVA glyphs in the alphabet.
For example, here is the probability vector for f1r:
1r 28 lines {‘a’: 0.08917835671342686, ‘c’: 0.08216432865731463, ‘e’: 0.05110220440881764, ‘d’: 0.06212424849699399, ‘f’: 0.00501002004008016, ‘i’: 0.08617234468937876, ‘h’: 0.12324649298597194, ‘k’: 0.045090180360721446, ‘*’: 0.012024048096192385, ‘m’: 0.001002004008016032, ‘l’: 0.03507014028056112, ‘o’: 0.11923847695390781, ‘n’: 0.050100200400801605, ‘p’: 0.012024048096192385, ‘s’: 0.06412825651302605, ‘r’: 0.04408817635270541, ‘t’: 0.03907815631262525, ‘y’: 0.07915831663326653}
(This reads as glyph “a” appears 8.9% of the time on f1r, glyph “c” 8.2% of the time, and so on.)
The question is: how similar are these frequency distributions amongst all the folios? Using tSNE (implemented in Scikit learn here: http://scikit-learn.org/stable/modules/generated/sklearn.manifold.TSNE.html) we can try to find a 3D arrangement of all the folios that minimises the glyph frequency vector difference between nearby folios.
Here’s a typical result: each folio appears as a point in 3D space …
 The colour coding is: red dots are folios that Currier identified as “Language A”, blue are “Language B”, and the remaining black dots do not have an assignment.
The colour coding is: red dots are folios that Currier identified as “Language A”, blue are “Language B”, and the remaining black dots do not have an assignment.
It’s clear that the red and blue are well separated, reinforcing Currier’s assignments. Thus this is independent support of Currier’s theory.
There are a couple of notable features:
- f57r and f57v are labelled as Language A (red) – but it looks like they should be labelled as Language B (blue)
- The unassigned folios (black dots) look like they are all Language B
Folios of the Voynich Manuscript, Glyph Colours
Edit Distance for Word Positions
The edit distance between two words is the number of edits needed to convert between the words. For example, the edit distance between “banana” and “bahama” is 2.
I looked at the average edit distance (the Levenshtein measure) between words on each line of each folio in the Herbal A and Herbal B sections. Here are the results:


How to interpret these plots
There is one square per word and line position: the top left square corresponds to the average edit distance between word 1 and word 2 on all the folios. The next square in the that row corresponds to the average edit distance between word 2 and word 3 on the folios.
Each square in the plot has a shade of gray: the darker the shade, the bigger the average edit distance.
One conclusion is that for both sets of folios, there is a big edit distance between the first and second words on the folios: the words are very dissimilar.
Another conclusion is that similar words (lighter shade of gray) tend not to occur in the first line, or as the first words.
Alfonso X’s Lapidario: Stones, Stars and Colours
I’ve been down a bit of rabbit hole over the last couple of days which others may have already been down. I was looking once more at the Zodiac folios, in particular Taurus. The Taurus Light and Dark folios are both marked “may” in, as often remarked, a later hand. There are 15 figures in each Taurus folio, for a total of 30. However, as we well know, May has 31 days, so the figures probably don’t represent days. I thus went in search of 30-way splits of Zodiac signs ….
Alfonso X’s Lapidario
Looking at this old Spanish illustrated manuscript:
“Tratados de Alfonso X sobre astrología y sobre las propiedades de las piedras”
which is a treatise on astrology and the importance of stones/gems etc., we can see a circular Taurus diagram with 30 divisions.

Each of these divisions is associated with a stone, of a noted colour, and one or a few stars in a constellation. There is a lengthy description of each division, its stone, its stars, the various ailments the stone cures, when the stone should be used, et cetera. There is a Spanish transcription of the text here, which I found very useful (combined with Google Translate):
Since a plausible language match to the month spellings as written in the Zodiac folios is Occitan which at one point covered part of Spain (please correct me on this, as I’m not sure), there seems to be a compelling regional match here, but I can’t quite figure it out.
From what I’ve read, Alfonso X assembled a team of scholars from all world regions, who worked on documents on a variety of topics. This website says of the Lapidario: “The Lapidario is a thirteenth century Castilian translation sponsored by King Alfonso X el Sabio, the Learned. The translation was done from an Arabic text which in turn is said to have been translated by the mysterious Abolays from an ancient text in the “Chaldean language””
Matching Stone Colours
Anyway, my first approach was to try to match the colours of the headgear or tunics of the clothed figures in the Taurus Light folio to the colours of the first and second fifteen stones mentioned in the Lapidario. It’s a little tricky, because although the stones are numbered, we don’t know which is figure 1 in the Taurus Light folio, and whether the inner ring precedes the outer. Even so, the patterns of colours in the stones sequence might reveal a match. I drew a blank.
Matching Stones with Voynich Star Labels
My second approach was to try to match the names of the stones with the labels on the figures, to see if there was some correlation between the label length, or its initial glyph, with the stones’ names. Very tricky.
Some of the stones that appear in the Taurus set of 30 also appear in other Zodiac signs in the Lapidario. For example, the ninth stone in Taurus is “esmeri(l)” (Latin), and esmeril is also the third stone of Libra, and the second stone of Aquarius.
This leads to the obvious question: is there a Figure in the both the Voynich Taurus and Libra roundels (Aquarius is missing) that shares the same label? If so, might that label be “esmeril”? And, are there other stones that appear in more than one sign which might be matched to duplicate stones in the Lapidario?
(As an aside, regarding the stones and colours, I was struck by the third stone of Taurus, called “camorica”, which is scarlet in colour and associated with the Pleiades.)
Another promising avenue is to compare the shapes and orientations of the stars in the constellations as they appear in the VM with how they appear in the Lapidario. Since the Pleiades are mentioned in the Lapidario, are they illustrated there, and does its illustration of the cluster match the apparent drawing of it in the VM (which differs in detail from its actual appearance in the night sky)? I need to investigate further, but my suspicion is that others have already been down this path 🙂
Chaldean Stones
I extracted the Chaldean stone names for each Zodiac sign, from the transcription I linked to above. The stones for Aries are shown below, as an example. (The whole set is available if anyone wants it.)
The first 12 sections in the Lapidario list the 30 stones for each zodiac sign, but a few signs appear to be truncated: Leo has only one stone, Pisces only has two stones, and Aquarius only 28.
There follow more sections, again one for each sign, but these each have only three stones. I’m not clear what they represent. I posted about all this at Voynich Ninja, and MarcoP was able to explain. Others also chimed in with some useful comments. The discussion is here.
Anyway, following those sections are several more that cover the stones of Saturn (4 stones), Jupiter (4 stones), Mars (4 stones), Venus (24 stones), Sun (9 stones) and Mercury (17 stones).
Here is an extract of the list I extracted for all the Zodiac stones: this is for Aries.
ARIES 1 magnitad 2 zurudica 3 gagatiz 4 miliztiz 5 centiz 6 movedor 7 goliztiz 8 telliminuz 9 milititaz 10 huye de la leche 11 alj?far 12 anetatiz 13 beruth 14 piedra de cinc 15 tira el oro 16 chupa la sangre 17 parece en la mar cuando sube Marte 18 tira el vidrio 19 annora 20 yzf 21 cuminon 22 astarnuz 23 belyniz 24 gaciuz 25 azufaratiz 26 abietityz 27 lubi 28 ceraquiz 29 berlimaz 30 annoxatir
In total I count 301 stones in the Lapidario’s Zodiac section, of which 291 are unique to a sign. The remainder appear more than once as follows:
bezaar [(9, 'G\x83MINIS'), (11, 'G\x83MINIS')] azarnech [(12, 'SAGITARIO'), (13, 'SAGITARIO')] pez [(7, 'LIBRA'), (30, 'LIBRA')] plomo [(18, 'VIRGO'), (13, 'CANCRO')] calcant [(10, 'VIRGO'), (11, 'VIRGO')] aliaza [(23, 'TAURO'), (29, 'TAURO')] parece en la mar [(15, 'SAGITARIO'), (15, 'TAURO'), (17, 'G\x83MINIS'), (17, 'ACUARIO')] de la serpiente [(12, 'LIBRA'), (7, 'G\x83MINIS')]
e.g. “bezaar” is the 9th and the 11th stone in Gemini, “de la sepiente” is the 12th stone in Libra and the 7th in Gemini.
Turning to the Voynich Zodiac, I count 298 unique star labels of which 269 are unique to a sign. The labels that appear more than once are:
otal dar ['71r', '70v2'] Aries (Light) , Pisces , otal ['72r2', '73r'] Gemini , Scorpio , okeey ary ['72r1', '72r2'] Taurus (Dark) , Gemini , okal ['73v', '72r2', '72r2'] Sagittarius , Gemini , Gemini , okeos ['73v', '73r', '73r'] Sagittarius , Scorpio , Scorpio , okeoly ['70v2', '72v1'] Pisces , Libra , otaly ['70v2', '72v3', '73r'] Pisces , Leo , Scorpio , okaram ['70v2', '72r2'] Pisces , Gemini , okoly ['70v1', '72v3'] Aries (Dark) , Leo , okalar ['72r3', '72r2'] Cancer , Gemini , okary ['72v3', '73r'] Leo , Scorpio , okam ['72r2', '72v3'] Gemini , Leo , okeody ['73v', '73v', '73r', '72v2'] Sagittarius , Sagittarius , Scorpio , Virgo , ykey ['73v', '73v'] Sagittarius , Sagittarius , okaly ['70v2', '72r2', '72r2', '72v3'] Pisces , Gemini , Gemini , Leo , okaldy ['72r2', '72v3'] Gemini , Leo , otaraldy ['72r1', '72r2'] Taurus (Dark) , Gemini , otoly ['72v3', '73r'] Leo , Scorpio , oky ['73v', '72v3', '73r'] Sagittarius , Leo , Scorpio , oteody ['73v', '73v'] Sagittarius , Sagittarius , okedy ['72v1', '73r'] Libra , Scorpio ,
e.g. “otal dar” appears as a label on both the Aries(Light) and Pisces zodiac chart.
If the Voynich Zodiac charts are indeed showing stones (and the figure/star labels are their names), then there should be good matches between the two lists above.
One potential match is:
azarnech [(12, 'SAGITARIO'), (13, 'SAGITARIO')] ykey ['73v', '73v'] Sagittarius , Sagittarius ,
However, the two labels “ykey” on f73v are not adjacent, which they should be if they are stones 12 and 13.
Another:
azarnech [(12, 'SAGITARIO'), (13, 'SAGITARIO')] oteody ['73v', '73v'] Sagittarius , Sagittarius ,
in this case, the two labels “oteody” on f73v are adjacent to one another, but the figures/stars they label are in the group of four at the top of the folio: it’s a stretch to think their locations are 12th and 13th.
To be continued ….
Are the Glyphs placed in specific folio locations?
Based on a lot of circumstantial evidence related to the weirdness of the Voynich text (such as the odd repeating words, the curious faintness and boldness of some glyphs, and the sometimes curious positioning of text words and lines), it appears that the folios were perhaps not written Left to Right (or Right to Left) and Top to Bottom.
Instead, suppose the scribe started each folio with a prescription: for example “put an h-Gallows at the top left, then put a c in the middle of the folio, then a 9 at the end of the last line”, and so on. This would be sort of like filling out the answers to a bizarre crossword puzzle.
If there was such a prescription, might it explain some of the Voynich text features?
In the following selected charts I’m showing a virtual folio from the Recipes section. Each chart has lines and columns. Line 1 position 1 is the top left of the folio. Let’s look at the chart folio for Glyph “o”:
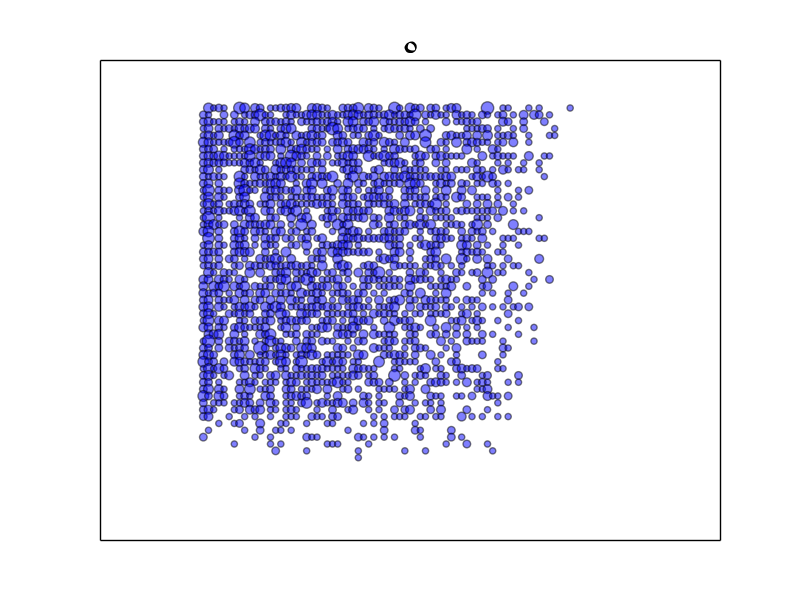
Each disc indicates that the “o” appears at least twice in that location in the Recipes. The size of the disc indicates how many times it appears there: the bigger the disc, the more times it appeared. The random appearance of the chart suggests that “o” is not placed on the page in any particular pattern.
Let’s now look at the “s” glyph:

Here it is clear that this glyph vastly prefers the first column, but not the first line. It is infrequently found elsewhere on the folio. In contrast, take a look at the rare glyphs (I just call them “?”):

These abhor the early columns, and love the ends of the lines. They also seem to prefer the ends of the first lines (notice a little cluster there). Perhaps they hate the “s” glyphs…
The “4” glyph:
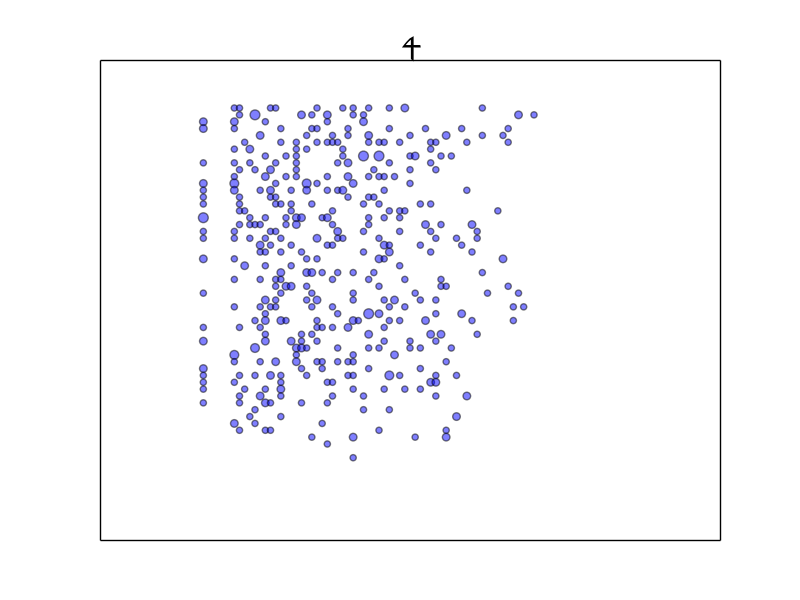
The gap after the first column is explained by how “4” only appears at the start of a word.
Here are some more glyphs:





No conclusions here, as usual!
Addendum: the distribution for “c”:

Common Words in Language A that are Rare in Language B
The question was posed: which words are common in Language A but rare in Language B? And vice versa.
For this study I used the Herbal/Balneo folios that are Language A and B respectively (folios 1-25 and 75-84).
There are around 2900 unique words in total, with around 1600 being used in Language A, and 1630 in Language B.
Here are the results. The tables show the words in order of decreasing value of the frequency in A (B) divided by the frequency in B (A), and show the number of occurrences of each word in both Languages.

Common in A, rare in B

Common in B, rare in A
Conclusion? I have no idea … for now.
Language “A” and “B” Conversions
This is an update to my previous two posts on this topic.
I have been concentrating on searching for the correspondence between glyphs used in Language A, and glyphs used in Language B. As a reminder, the method is to take all words in, say, Language A, and “convert” them to words in Language B by changing the glyphs according to a candidate mapping table. The frequency of the converted Language B words is then compared with the original Language A words: the closer the frequencies, the better the mapping match.
Method Check using only Language A words
As a check of the method, I took the Herbal folios 1-25 (all in Language A) and split them into two groups: 1-12 and 13-25, and I then artificially labelled the latter group as Language B. Then I ran the matching procedure, which produced the following result:
Epoch 62 Best chromosome 0 Value= 5.62272615159e-05 Chromosome ['o', '9', '1', 'i', '8', 'a', 'e', 'c', 'k', 'y', 'h', 'N', '2', '4', 's', 'g', 'p', '?', 'K', 'H'] ngramsA ['o', '9', '1', 'i', '8', 'a', 'e', 'c', 'h', 'y', 'k', 'N', '2', '4', 's', 'g', 'p', '?', 'K', 'H']
This is good and reassuring, since it shows that the words in folios 13-25 have essentially the same frequency distribution when their glyphs are mapped to the same glyphs in folios 1-12.
Removal of Glyph Variants in Voyn_101
As the tests progressed, it became clear that some of the glyphs GC defined in Voyn_101 were in fact variants of more common glyphs. The most obvious were the “m”, “n”, “N” glyphs mentioned before – with these included, the conversions between Language B and Language A were of much poorer quality than if they were expanded to “iiN”, “iN” and “iiiN” respectively. After some time weeding out these variants, the following table was arrived at:
seek = ["3", "5", "+", "%", "#", "6", "7", "A", "X",
"I", "C", "z", "Z", "j", "u", "d", "U", "P",
"Y", "$", "S", "t", "q",
"m", "M", "n", "Y", "!", ")", "*", "b", "J", "E", "x", "B", "D", "T", "Q", "W", "w", "V", "(", "&"]
repl = ["2", "2", "2", "2", "2", "8", "8", "a", "y",
"ii", "cc", "iy", "iiy", "g", "f", "ccc", "F", "ip",
"y", "s", "cs", "s", "iip",
"iiN", "iiiN", "iN", "y", "2", "9", "p", "y", "G", "c", "y", "cccN", "ccN", "s", "p", "h", "h", "K", "9", "8"]
I am very confident that the glyphs remaining after using the above conversion table are the base set. The base set of glyphs is thus:
Language A frequency order: 'o', 'c', '9', '1', 'a', '8', 'e', 'i', 'h', 'y', 'k', 's', '2', 'N', '4', 'g', 'p', '?', 'K', 'H', 'f', 'G', 'F', 'L', 'l', 'v', 'r', 'R' Language B frequency order: 'c', 'o', '9', 'a', '8', 'e', '1', 'h', 'i', 'y', 'k', '2', 'N', 's', '4', 'g', 'p', 'f', '?', 'H', 'K', 'G', 'F', 'l', 'L', 'R', 'r', 'v'
where “?” represents all very rare glyphs (such as the “picnic table” glyph). There are thus 27 glyphs (15 gallows and 12 regular) excluding the rare special glyphs like the picnic table.
Glyph Mixing Between A and B
I ran many trials using the base set of glyphs, comparing various sections of the VMs written in the different hands. In particular, the following folio collections were defined:
Special = {'HerbalRecipeAB': range(107,117) + range(1,26),
'HerbalAB': range(1,57),
'HerbalBalneoAB': range(1,26) + range(75,85),
'HerbalAstroAB': range(1,13) + range(67,75),
'PharmaRecipeAB': [88,89,99,100,101,102] + range(103,117),
'AllAB': range(1,117)
}
The collection I used the most was the one called “HerbalBalneoAB”, which contains Herbal folios written in Language A, and Balneo folios written in Language B. The nice feature of this collection is that the number of words is around the same for both Languages, which makes comparing counts very easy:
Total words = 2846 Total Language A = 1581 Total Language B = 1584
As an example, here is a trial result for HerbalBalneoAB:
Language B ['o', '9', '1', 'a', 'i', 'f', 'c', 'y', 'h', 'e', 'K', 'N', '2', 's', '4', 'g', 'p', '8', 'k', 'H'] Language A ['o', '9', '1', 'a', 'i', '8', 'c', 'e', 'h', 'y', 'k', 'N', '2', 's', '4', 'g', 'p', 'K', '?', 'H']
In all the tests I ran, there were some common features in the results:
- Mixing between “e” and “y” – when writing Language A, the use of “e” appears to be equivalent to the use of “y” in Language B, and vice versa
- Mixing between 8,f,F,k,K,g,G,r,R,? and so on – the Gallows glyphs swap amongst themselves, and “8”
Just about all trials showed the “e”/”y” mixing. Tony Gaffney pointed out that these two glyphs are quite similar in stroke construction. The appearance of “8” amongst the swapping Gallows glyphs is curious.
The Relationship Between Currier Languages “A” and “B”
Captain Prescott Currier, a cryptographer, looked at the Voynich many moons ago, and made some very perceptive comments about it, which can be seen here on Rene Zandbergen’s site.
In particular, he noticed that the handwriting was different between some folios and others, and he also noticed (based on glyph/character counts) that there were two “languages” being used.
When I first looked at the manuscript, I was principally considering the initial (roughly) fifty folios, constituting the herbal section. The first twenty-five folios in the herbal section are obviously in one hand and one ‘‘language,’’ which I called ‘‘A.’’ (It could have been called anything at all; it was just the first one I came to.) The second twenty-five or so folios are in two hands, very obviously the work of at least two different men. In addition to this fact, the text of this second portion of the herbal section (that is, the next twenty-five of thirty folios) is in two ‘‘languages,’’ and each ‘‘language’’ is in its own hand. This means that, there being two authors of the second part of the herbal section, each one wrote in his own ‘‘language.’’ Now, I’m stretching a point a bit, I’m aware; my use of the word language is convenient, but it does not have the same connotations as it would have in normal use. Still, it is a convenient word, and I see no reason not to continue using it.
We can look at some statistics to see what he was referring to. Let’s compare the most common words in Folios 1 to 25 (in the Herbal section, Language A, written in Hand 1) and in Folios 107 to 116 (in the Recipes section, Language B, written in a different Hand):

Comparison between word frequencies in Languages A and B
So, for example, in Language A the most common word is “8am” and it occurs 192 times in the folios, whereas in Language B the most common word is “am”, occuring 137 times.
We might expect that these are the same word, enciphered differently. The question then is, how does one convert between words in Language A and words in Language B, and vice versa? In the case of the “8am” to “am” it’s just a question of dropping the “8”, as if “8” is a null character in Language A. In the case of the next most popular words, “1oe”(A) and “1c89″(B) it looks like “oe”(A) converts to “c89″(B). And so on.
If we look at the most popular nGrams (substrings) in both Languages, perhaps there is a mapping that translates between the two. Perhaps the cipher machinery that was used to generate the text had different settings, that produced Language A in one configuration, and Language B in another. Perhaps, if we look at the nGram correspondence that results in the best match between the two Languages, a clue will be revealed as to how that machinery worked.
This involves some software (I’m using Python now, which is fun). The software first calculates the word frequencies for Language A and B in a set of folios (the table above is an output from this stage). It then calculates the nGram frequencies for each Language. Here are the top 10:

The software then runs a Genetic Algorithm to find the best mapping between the two sets of nGrams, so that when the mapping is applied to all words in Language B, it produces a set of words in Language A the frequencies of which most closely match the frequencies of words observed in Language A (i.e. the frequencies shown in the first table above).
Here is an initial result. With the following mapping, you can take most common words in Language B, and convert them to Language A.

Table for converting between a Language B word and a Language A word
A couple of remarks. This is an early result and probably not the best match. There are some interesting correspondences :
- “9” and “c” are immutable, and have the same function
- Another interesting feature is that “4o” in Language B maps to “o” in Language A, and vice versa!
- in Language B, “ha” maps to “h” in Language A, as if “a” is a null
In the Comments, Dave suggested looking at word pair frequencies between the Languages. Here is a table of the most common pairs in each Language.

Common word pairs in Languages A and B
For clarity, I am using what I call the “HerbalRecipesAB” folios for this study i.e.
Using folios for HerbalRecipeAB : [107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25]
More results coming …
