Archive
Fun with Grove Words and Cipher Wheels
What is a Grove word? The answer is a little fuzzy, but simplistically a Grove word is a VMS word that begins with one of the gallows glyphs. These words are often page or paragraph initial. Emma May Smith has a good explanation in her recent blog entry.
Mr. Grove observed the peculiar feature that some words beginning with a gallows glyph are also valid words if you remove the gallows glyph. For example, the word EVA kodaiin starts with gallows k, and odaiin is also a valid word.
It turns out that if you look at all words in the VMS, 46% of them have this property: remove the first glyph and you are left with a valid VMS word. Compare this with English, where only around 8% of words produce valid words if you remove the first letter. Making up the 46% we have 38% from non-Grove words (i.e. non-gallows initial), and 8% from Grove words.
To round out the statistics, about 13% of all VMS words have an initial gallows glyph.

Consider the nine wheels above, where one of the wheels contains gallows glyphs, and the other wheels contain other glyphs. These wheels can be selected in 29 -1 i.e. 511 different ways, to make words of length between 1 and 9.
The probability of selecting wheel 3 as the first wheel for the word is about 12.5%. In other words, with these 9 wheels, 12.5% of the time we’d create a gallows-initial “Grove” word – very close to what we observe in the VMS (13%). In fact, this figure of 12.5% is independent of the number of cipher wheels: as long as there are at least three wheels and they are used left to right, and the gallows glyphs fully occupy the third wheel, then 12.5% of the generated words will be Grove types.
As a corollary, it’s clear that for Grove types generated with the wheels, removing the first glyph will produce a valid word, as it is equivalent to generating a word starting at wheel 4 or later.
So what of the 54% of VMS words that are non-Grove, i.e. removing the initial glyph does not produce a valid VMS word? This can be explained if the number of different words used and written in the VMS is simply less than the total number of possible words that the author’s wheels can produce. What is the expected vocabulary size if we know there are 7,552 words written in the VMS (Takeshi), and we are missing 54% of them? It is simply 1.54 x 7,552 = 11,630 words, or thereabouts.
(Aside: the wheels above could just as easily be represented and used as a table with nine columns.)
In summary, “Grove” words (gallows initial) are ~13% of all words in the Voynich manuscript, and this fraction is what you’d expect if the text was produced using cipher wheels.
Nine Cipher Wheels
UPDATE (12 Aug 2021): the plots and results discussed in this post used a version of EVA that replaces some common glyph sequences by a single glyph, namely ch, sh, ain, aiin, and qo. Clearly, this tends to reduce the average word length. A later post will discuss the distributions obtained with words without this simplification.
The lengths of VMS words follow the binomial distribution for 9, as observed by Stolfi, and as discussed in Rene’s recent paper. This binomial distribution can be obtained from a set of 9 cipher wheels, where each wheel has a 50% chance of contributing one of its glyphs to the word being assembled, and the lengths of the resulting words plotted:

In the above plot, the orange line shows the distribution of word lengths from EVA, and the blue line shows the distribution of word lengths obtained by using the following set of 9 cipher wheels to generate a large number of random words:

With the cipher wheels shown, about 50% of the generated words will contain a gallows glyph, and this is, perhaps not coincidentally, the case in the VMS text, too.
Using the same technique as applied in my earlier blog post, where I looked at the counts between gallows glyphs in the VMS text, we can look at the same distributions for words generated with the above wheels, assembled into lines of text, and ignoring spaces between words. The results are very similar, and shown below.
Here are the others:



The Gallows and Benched Gallows
Let’s explore the number of glyphs that tend to appear between the Gallows glyphs. As a reminder, the Gallows glyphs are:

To illustrate the counting method, an example line of VMS text is:

The line above can be represented as
Gxxxx-xxGxxx-Gxx-xGxxx-xx-Gxxxx-xGxxxx
where “x” denotes any non-Gallows glyph, “G” denotes any one of the eight Gallows glyphs, and “-” denotes a space. The counting we’ll use ignores spaces and only counts the “x”s. For this study we only consider lines of text as separate units – no counting across line breaks.
So, the count of glyphs between the initial G and the second G is 6, and between the second G and the third G is 3. For the last G in the line, we count the number of glyphs following: so in the line above the count is 4.
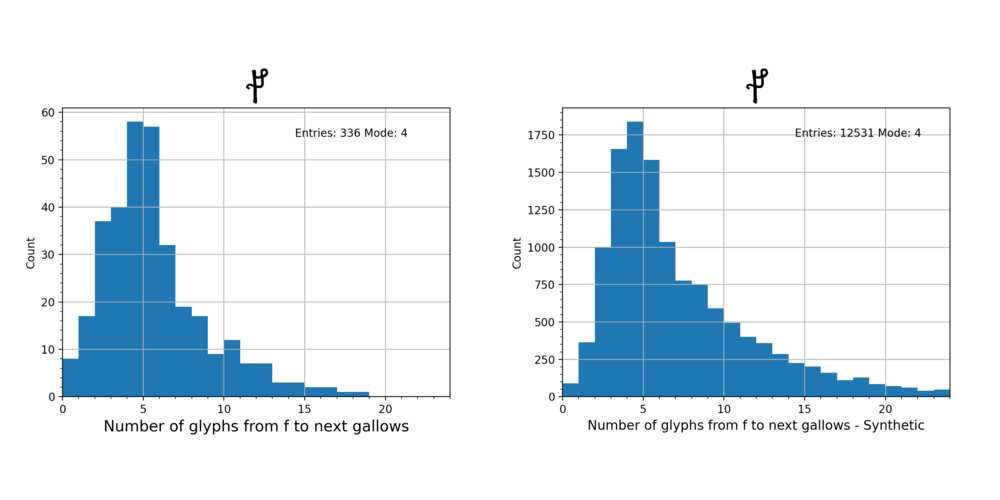
First of all, we’ll look at the differences between the distributions of counts for the four unbenched Gallows glyphs. The “Mode” value is the most likely/common count.



Some remarks about these distributions:
- The sequence GG i.e. where the count is zero, is very rare: this means Gallows glyphs rarely are found next to one another. (Just as capital letters are uncommonly found together in English prose.)
- Most often, there are between 5 and 7 glyphs that follow a Gallows before the next Gallows appears.
- The shapes of the distributions are similar: they have Full Width Half Maximum (FWHM) values of around 6 glyphs, and long tails.
- The distributions are unrelated to VMS word lengths, as we are not counting any spaces.
Observations
- Gallows EVA p and f tend to be followed by one or more glyphs than EVA t and k (the Modes are 7, 6, 5, 5 respectively).


What do EVA p and f have in common that EVA t and k do not?

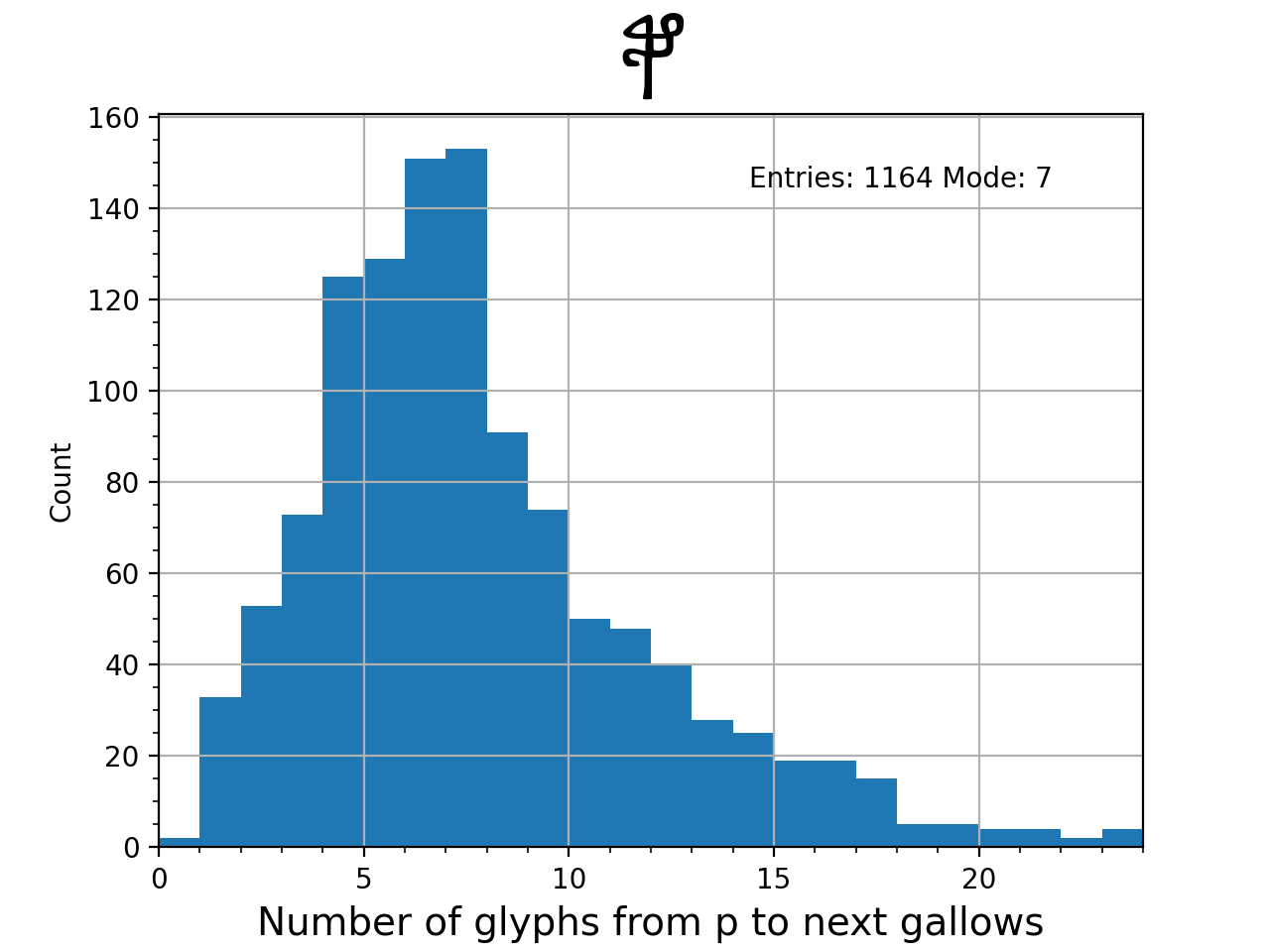
Now let’s look at the Benched Gallows. I will call these T, K, P, F: in EVA they are cth ckh cph cfh. The same counting method is used as above.




Again, some features of the distributions:
- The sequence GG is very rare.
- G is most likely followed by 3 glyphs.
- FWHM are between 3 and 4 glyphs.
- Unlike the un-benched gallows, the count of glyphs following is apparently unrelated to the curlicrossbar.
Observations
The number of glyphs that follow a benched Gallows is typically 3, before the next Gallows is encountered. For un-benched Gallows, this number is typically 5 to 7. This does not enthusiastically support the hypothesis that the benched Gallows are simply the same as un-benched gallows with the two adjoining glyphs written separately. For example, take a common sequence, with 7 intervening glyphs:
pxxxxxxxp
is clearly not equivalent to the common sequence for benched of:
PxxxP
since PxxxP written as un-benched would be
cphxxxcph
which only has 5 intervening glyphs. On the other hand there are some relatively common sequences such as:
kxxxxxk
which is equivalent to the common sequence:
KxxxK
The discussion above begs the question: what are the count distributions for the number of glyphs that lie between specific pairs of un-benched or benched Gallows? Is there some peculiarity of the counts between different pairs of gallows?
Folios of the Voynich Manuscript, Glyph Colours
Are the Glyphs placed in specific folio locations?
Based on a lot of circumstantial evidence related to the weirdness of the Voynich text (such as the odd repeating words, the curious faintness and boldness of some glyphs, and the sometimes curious positioning of text words and lines), it appears that the folios were perhaps not written Left to Right (or Right to Left) and Top to Bottom.
Instead, suppose the scribe started each folio with a prescription: for example “put an h-Gallows at the top left, then put a c in the middle of the folio, then a 9 at the end of the last line”, and so on. This would be sort of like filling out the answers to a bizarre crossword puzzle.
If there was such a prescription, might it explain some of the Voynich text features?
In the following selected charts I’m showing a virtual folio from the Recipes section. Each chart has lines and columns. Line 1 position 1 is the top left of the folio. Let’s look at the chart folio for Glyph “o”:
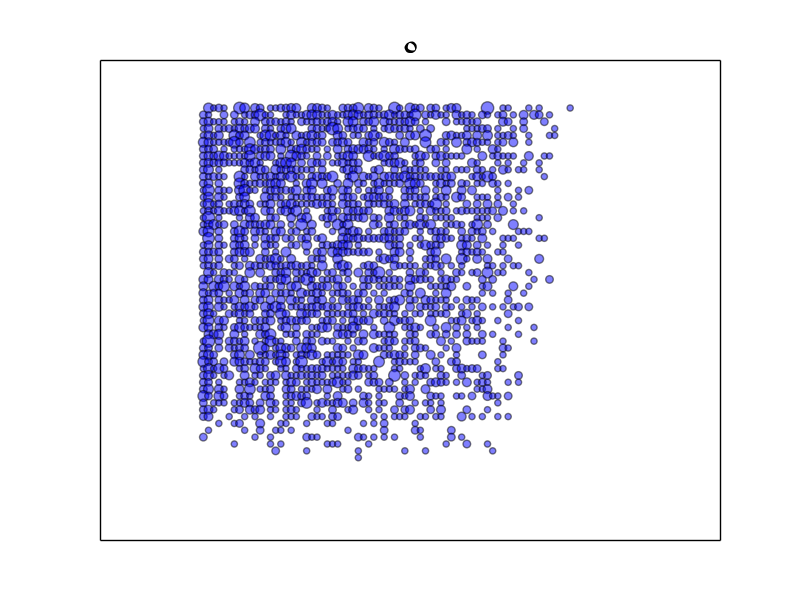
Each disc indicates that the “o” appears at least twice in that location in the Recipes. The size of the disc indicates how many times it appears there: the bigger the disc, the more times it appeared. The random appearance of the chart suggests that “o” is not placed on the page in any particular pattern.
Let’s now look at the “s” glyph:

Here it is clear that this glyph vastly prefers the first column, but not the first line. It is infrequently found elsewhere on the folio. In contrast, take a look at the rare glyphs (I just call them “?”):

These abhor the early columns, and love the ends of the lines. They also seem to prefer the ends of the first lines (notice a little cluster there). Perhaps they hate the “s” glyphs…
The “4” glyph:
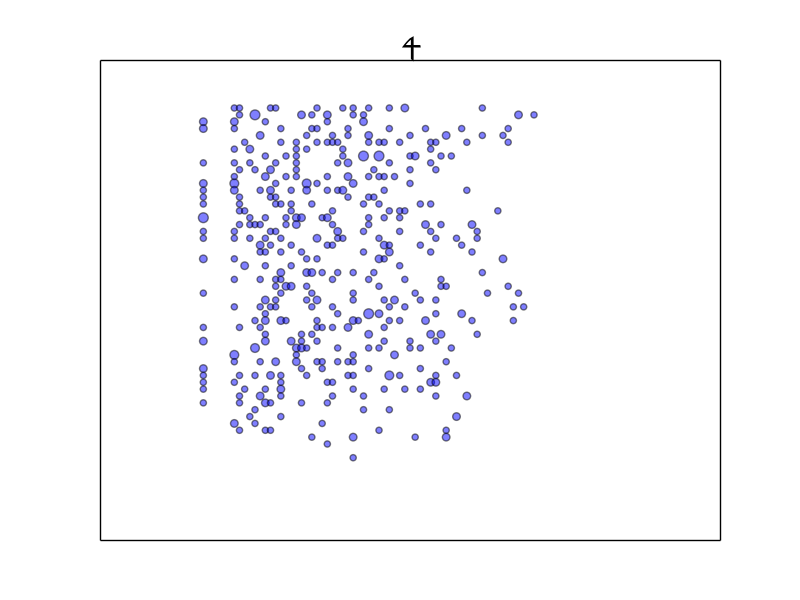
The gap after the first column is explained by how “4” only appears at the start of a word.
Here are some more glyphs:





No conclusions here, as usual!
Addendum: the distribution for “c”:

Entropy of the Voynich text
The Shannon Entropy of a string of text measures the information content of the text. For text that is completely random i.e. where the appearance of any character is as likely as the appearance of any other, the entropy (or “disorder”) is high. For a text which is a long string of identical characters, for example, the entropy is low.
Mathematically, the Shannon Entropy is defined as:
Entropy = –ΣiN probi * Log( probi)
where probi is the frequency of the i’th character in the text, and the sum is over all the characters.
If the Voynich text is randomly created (by whatever means), we’d expect it to have high entropy (i.e. be very disordered). What we in fact find is that the text is ordered, with low Entropy, and is rather more ordered than English, for example. The result of comparing the Voynich text with several other texts in different languages is shown in the table below.
| Language | Source | Entropy |
|---|---|---|
| Voynich | GC’s Transcription | 3.73 |
| French | Text from 1367 | 3.97 |
| Latin | Cantus Planus | 4.05 |
| Spanish | Medina 1543 | 4.09 |
| German | Kochbuch 1553 | 4.15 |
| English | Thomas Hardy | 4.21 |
| Early Italian | Divine Comedy 1300 | 4.23 |
| None | Random characters | 6.01 |
The last entry in the table shows the Entropy for a random text – and is getting on for double the Entropy of the Voynich.
Language A and B Again
A tentative conclusion from comparing Language A and Language B is that the non-gallows glyphs are used in the same way in both Languages.

Language “A” and “B” Conversions
This is an update to my previous two posts on this topic.
I have been concentrating on searching for the correspondence between glyphs used in Language A, and glyphs used in Language B. As a reminder, the method is to take all words in, say, Language A, and “convert” them to words in Language B by changing the glyphs according to a candidate mapping table. The frequency of the converted Language B words is then compared with the original Language A words: the closer the frequencies, the better the mapping match.
Method Check using only Language A words
As a check of the method, I took the Herbal folios 1-25 (all in Language A) and split them into two groups: 1-12 and 13-25, and I then artificially labelled the latter group as Language B. Then I ran the matching procedure, which produced the following result:
Epoch 62 Best chromosome 0 Value= 5.62272615159e-05 Chromosome ['o', '9', '1', 'i', '8', 'a', 'e', 'c', 'k', 'y', 'h', 'N', '2', '4', 's', 'g', 'p', '?', 'K', 'H'] ngramsA ['o', '9', '1', 'i', '8', 'a', 'e', 'c', 'h', 'y', 'k', 'N', '2', '4', 's', 'g', 'p', '?', 'K', 'H']
This is good and reassuring, since it shows that the words in folios 13-25 have essentially the same frequency distribution when their glyphs are mapped to the same glyphs in folios 1-12.
Removal of Glyph Variants in Voyn_101
As the tests progressed, it became clear that some of the glyphs GC defined in Voyn_101 were in fact variants of more common glyphs. The most obvious were the “m”, “n”, “N” glyphs mentioned before – with these included, the conversions between Language B and Language A were of much poorer quality than if they were expanded to “iiN”, “iN” and “iiiN” respectively. After some time weeding out these variants, the following table was arrived at:
seek = ["3", "5", "+", "%", "#", "6", "7", "A", "X",
"I", "C", "z", "Z", "j", "u", "d", "U", "P",
"Y", "$", "S", "t", "q",
"m", "M", "n", "Y", "!", ")", "*", "b", "J", "E", "x", "B", "D", "T", "Q", "W", "w", "V", "(", "&"]
repl = ["2", "2", "2", "2", "2", "8", "8", "a", "y",
"ii", "cc", "iy", "iiy", "g", "f", "ccc", "F", "ip",
"y", "s", "cs", "s", "iip",
"iiN", "iiiN", "iN", "y", "2", "9", "p", "y", "G", "c", "y", "cccN", "ccN", "s", "p", "h", "h", "K", "9", "8"]
I am very confident that the glyphs remaining after using the above conversion table are the base set. The base set of glyphs is thus:
Language A frequency order: 'o', 'c', '9', '1', 'a', '8', 'e', 'i', 'h', 'y', 'k', 's', '2', 'N', '4', 'g', 'p', '?', 'K', 'H', 'f', 'G', 'F', 'L', 'l', 'v', 'r', 'R' Language B frequency order: 'c', 'o', '9', 'a', '8', 'e', '1', 'h', 'i', 'y', 'k', '2', 'N', 's', '4', 'g', 'p', 'f', '?', 'H', 'K', 'G', 'F', 'l', 'L', 'R', 'r', 'v'
where “?” represents all very rare glyphs (such as the “picnic table” glyph). There are thus 27 glyphs (15 gallows and 12 regular) excluding the rare special glyphs like the picnic table.
Glyph Mixing Between A and B
I ran many trials using the base set of glyphs, comparing various sections of the VMs written in the different hands. In particular, the following folio collections were defined:
Special = {'HerbalRecipeAB': range(107,117) + range(1,26),
'HerbalAB': range(1,57),
'HerbalBalneoAB': range(1,26) + range(75,85),
'HerbalAstroAB': range(1,13) + range(67,75),
'PharmaRecipeAB': [88,89,99,100,101,102] + range(103,117),
'AllAB': range(1,117)
}
The collection I used the most was the one called “HerbalBalneoAB”, which contains Herbal folios written in Language A, and Balneo folios written in Language B. The nice feature of this collection is that the number of words is around the same for both Languages, which makes comparing counts very easy:
Total words = 2846 Total Language A = 1581 Total Language B = 1584
As an example, here is a trial result for HerbalBalneoAB:
Language B ['o', '9', '1', 'a', 'i', 'f', 'c', 'y', 'h', 'e', 'K', 'N', '2', 's', '4', 'g', 'p', '8', 'k', 'H'] Language A ['o', '9', '1', 'a', 'i', '8', 'c', 'e', 'h', 'y', 'k', 'N', '2', 's', '4', 'g', 'p', 'K', '?', 'H']
In all the tests I ran, there were some common features in the results:
- Mixing between “e” and “y” – when writing Language A, the use of “e” appears to be equivalent to the use of “y” in Language B, and vice versa
- Mixing between 8,f,F,k,K,g,G,r,R,? and so on – the Gallows glyphs swap amongst themselves, and “8”
Just about all trials showed the “e”/”y” mixing. Tony Gaffney pointed out that these two glyphs are quite similar in stroke construction. The appearance of “8” amongst the swapping Gallows glyphs is curious.
The Relationship Between Currier Languages “A” and “B”
Captain Prescott Currier, a cryptographer, looked at the Voynich many moons ago, and made some very perceptive comments about it, which can be seen here on Rene Zandbergen’s site.
In particular, he noticed that the handwriting was different between some folios and others, and he also noticed (based on glyph/character counts) that there were two “languages” being used.
When I first looked at the manuscript, I was principally considering the initial (roughly) fifty folios, constituting the herbal section. The first twenty-five folios in the herbal section are obviously in one hand and one ‘‘language,’’ which I called ‘‘A.’’ (It could have been called anything at all; it was just the first one I came to.) The second twenty-five or so folios are in two hands, very obviously the work of at least two different men. In addition to this fact, the text of this second portion of the herbal section (that is, the next twenty-five of thirty folios) is in two ‘‘languages,’’ and each ‘‘language’’ is in its own hand. This means that, there being two authors of the second part of the herbal section, each one wrote in his own ‘‘language.’’ Now, I’m stretching a point a bit, I’m aware; my use of the word language is convenient, but it does not have the same connotations as it would have in normal use. Still, it is a convenient word, and I see no reason not to continue using it.
We can look at some statistics to see what he was referring to. Let’s compare the most common words in Folios 1 to 25 (in the Herbal section, Language A, written in Hand 1) and in Folios 107 to 116 (in the Recipes section, Language B, written in a different Hand):

Comparison between word frequencies in Languages A and B
So, for example, in Language A the most common word is “8am” and it occurs 192 times in the folios, whereas in Language B the most common word is “am”, occuring 137 times.
We might expect that these are the same word, enciphered differently. The question then is, how does one convert between words in Language A and words in Language B, and vice versa? In the case of the “8am” to “am” it’s just a question of dropping the “8”, as if “8” is a null character in Language A. In the case of the next most popular words, “1oe”(A) and “1c89″(B) it looks like “oe”(A) converts to “c89″(B). And so on.
If we look at the most popular nGrams (substrings) in both Languages, perhaps there is a mapping that translates between the two. Perhaps the cipher machinery that was used to generate the text had different settings, that produced Language A in one configuration, and Language B in another. Perhaps, if we look at the nGram correspondence that results in the best match between the two Languages, a clue will be revealed as to how that machinery worked.
This involves some software (I’m using Python now, which is fun). The software first calculates the word frequencies for Language A and B in a set of folios (the table above is an output from this stage). It then calculates the nGram frequencies for each Language. Here are the top 10:

The software then runs a Genetic Algorithm to find the best mapping between the two sets of nGrams, so that when the mapping is applied to all words in Language B, it produces a set of words in Language A the frequencies of which most closely match the frequencies of words observed in Language A (i.e. the frequencies shown in the first table above).
Here is an initial result. With the following mapping, you can take most common words in Language B, and convert them to Language A.

Table for converting between a Language B word and a Language A word
A couple of remarks. This is an early result and probably not the best match. There are some interesting correspondences :
- “9” and “c” are immutable, and have the same function
- Another interesting feature is that “4o” in Language B maps to “o” in Language A, and vice versa!
- in Language B, “ha” maps to “h” in Language A, as if “a” is a null
In the Comments, Dave suggested looking at word pair frequencies between the Languages. Here is a table of the most common pairs in each Language.

Common word pairs in Languages A and B
For clarity, I am using what I call the “HerbalRecipesAB” folios for this study i.e.
Using folios for HerbalRecipeAB : [107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25]
More results coming …
How was the Voynich Manuscript text written?
I’ve spent many happy hours poring over the text, and am convinced that it is not as “simple” as it appears (i.e. the “words” are not words at all). Here are some conjectures:
- The lines look like they are written left to right i.e. the glyphs were written down from left to right, but were not.
- The scribe started with the drawing and started writing glyphs at various positions on the page.
- The method used for choosing each glyph and for deciding its position involved a mechanical apparatus, perhaps a set of co-rotating cipher wheels that were used to convert each character in the Latin plaintext into a VMs glyph and page position
- The apparatus is set to a new starting position for each folio/page (so e.g. Bettony labels on the three folios the plant appears on are different)
- The density of ink is a clue to the order in which the glyphs were written (nib/quill freshly dipped and full of ink, or almost dry)
- At some point the scribe finishes writing the needed glyphs, and then fills out the spaces with pseudo-random words.
- There is no punctuation because what is seen are not words. What is seen makes no grammatical sense because the glyphs are not ordered and positioned linearly across the page.
- Perhaps the secret to unwinding the cipher is in the labels. The labels on one page are constrained to have been produced by the same initial position of the cipher apparatus, and they must come from the plaintext label.
There are so many clues as to what is going on, yet putting them all together is hugely challenging
For example, Jim Reeds suggested years ago that the order in which the text had been written on the sunflower page, f33v:

f33v
was first the text to the left of the left stalk, second the text in between the stalks, and finally the text to the right of the last stalk. This is compelling, since the ink density looks different, and the lines don’t line up well across the stalks. It becomes clearer if you saturate the image:

f33v Saturated
And in that image, what jumps out are the glyphs that are darker than the others. Those can be seen more clearly in black/white:

f33v monochrome drop
where the “o”, “y”, “8”, “e” stick out like sore thumbs. Most of those are in the left section, some in the middle, and fewer in the right. Why are these glyphs bolder, why are they inked more heavily? Were these the glyphs initially placed on the page, and contain the real information, and the rest, unimportant and pseudo-random, were all added later to make the text look “normal”?
